הקרב על התרגום: Google מול GPT 🥊

מודלי שפה, בעיקר מודלי שפה גדולים (LLMs) תורמים לנו ליום יום רבות. האתגר המרכזי שזיהיתי בפרוייקטים השונים הוא תחום הניטור-הערכה (Evaluation) על טיב תוצאות המודל: בבחירת המודל המתאים למשימה ובניטור ביצועי המודל בממשק מול הלקוח.
במאמר זה אציג לכם מחקר קצר שעשיתי, שעוסק בהשוואת תרגום Google Translate למול מודלי GPT-4o ו-GPT-4o mini. התוצאות מעניינות 🤩
הודעות #
מסד נתונים #
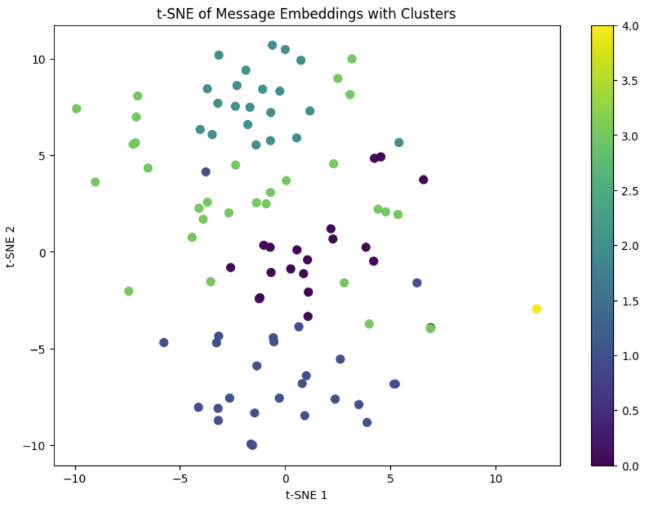
המחקר שלי נבע מצורך של פרוייקט נפרד, שעסק בריבוי הודעות בשפות שונות (לשם ההדגמה ניקח את ההודעות בערבית) ותרגומן לשפה זהה. ההודעות נטענות בזמן אמת ל-MongoDB. יש לנו כ-10 אלף הודעות. צירפתי מטה הודעות לדוגמא.
| content | timestamp | message_id | channel | _id |
|---|---|---|---|---|
| “أخبار عاجلة: زيادة أسعار النفط عالميًا” | 2024-11-04 09:15:00 | 1001 | News_Channel_1 | 1 |
| “التكنولوجيا الحديثة تغيّر شكل الحياة اليومية” | 2024-11-04 09:20:00 | 1002 | News_Channel_2 | 2 |
| “توقعات بطقس ممطر في نهاية الأسبوع” | 2024-11-04 09:25:00 | 1003 | News_Channel_1 | 3 |
| “مؤشرات اقتصادية تظهر تحسنًا طفيفًا” | 2024-11-04 09:30:00 | 1004 | News_Channel_3 | 4 |
| “الحكومة تعلن عن خطط جديدة لتطوير التعليم” | 2024-11-04 09:35:00 | 1005 | News_Channel_1 | 5 |
| “تحديثات حول حملة التطعيم الوطنية ضد الأمراض” | 2024-11-04 09:40:00 | 1006 | News_Channel_2 | 6 |
| “استثمارات جديدة في قطاع الطاقة المتجددة” | 2024-11-04 09:45:00 | 1007 | News_Channel_3 | 7 |
| “الرئيس يلقي خطابًا هامًا حول الاقتصاد” | 2024-11-04 09:50:00 | 1008 | News_Channel_1 | 8 |
| “الرياضة المحلية تشهد منافسات قوية هذا الموسم” | 2024-11-04 09:55:00 | 1009 | News_Channel_2 | 9 |
| “افتتاح معرض الفنون الدولي في العاصمة” | 2024-11-04 10:00:00 | 1010 | News_Channel_3 | 10 |
מחיר #
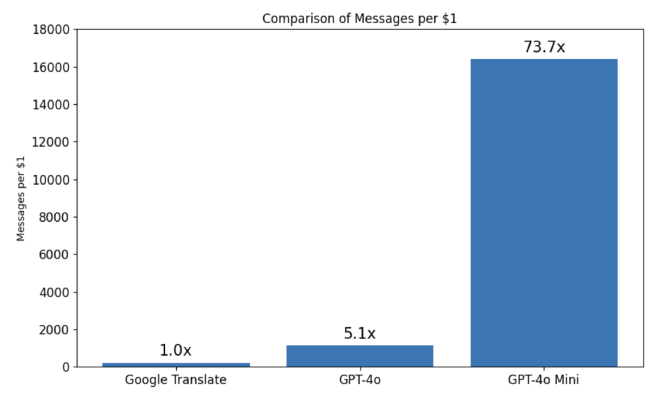
חישבתי סטטיסטית כמה הודעות ייכנסו ב-1$ בכל אחד מהשירותים. כמו שאפשר לראות, ההבדל בין Google Translate ל-GPT-4o יחסית קטן, אבל בהשוואה ל-GPT-4o mini מדובר על פער של פי 74; 16,400 הודעות לדולר במיני למול 223 הודעות לדולר בגוגל - חיסכון משמעותי ששווה העמקה.
Structued Output #
לפני שנמשיך במאמר, רציתי לספר על Structured Output מבית OpenAI, שהושק לפני שלושה חודשים. עד עכשיו, על מנת להגדיר פורמט קבוע של Response מהמודלי GPT, הינו מגדירים response_format מסוג json_object, יחד עם הסבר מפורט לפורמט של ה-JSON שקיוונו לקבל, וזהו.
Structured Output מאפשר לנו להתייחס ל-Response של המודלים כאובייקיטים, ברמת וודאות של 100%, ובכך להוריד כאבי ראש. בנוסף, עכשיו נגדיר את אותם האובייקטים כ-Pydandic. מרגישים קצת בלגן? בואו ניקח דוגמא.
דוגמא #
לשם ההדגמה, נבנה בוט שמקבל HTML ומזקק בעצמו את הכותרת, פסקאות, לינקים ותמונות. אני יודע שזה פתיר בעזרת Regex, אבל החלטתי לקחת דוגמא פשוטה.
שלב 1: Imports והגדרת מפתח OpenAI #
import openai
import os
import json
from dotenv import load_dotenv
from pydantic import BaseModel
from typing import List, Optional
# Load environment variables and set API key
load_dotenv()
openai.api_key = os.getenv('OPENAI_API_KEY')
כמו בכל סקריפט Python, תחילה נבצע מספר imports ונגדיר את המפתח ל-OpenAI, ששמרנו כמובן בסביבה ולא על גבי הקוד.
שלב 2: הגדרת Webpage #
class Webpage(BaseModel):
title: str
paragraphs: Optional[List[str]]
links: Optional[List[str]]
images: Optional[List[str]]
בדרך החדשה, אנחנו יכולים בצורה פשוטה לבנות אובייקט pydantic ולשלוח אותו למודל יחד עם ההודעות, ולקבל את התשובה על פי אותו האובייקט. כמו שאפשר לראות, למעט הכותרת, הגדרתי רשימה של משפטים אופציונליים, שייצגו את תוויות ה-HTML.
בעזרת שימוש ב-pydantic , נאמת ונהכריח את המודל לענות בפורמט הרצוי.
שלב 3: OpenAI Client #
class OpenAIClient:
def __init__(self, model: str = "gpt-4o-2024-08-06"):
self.model = model
def parse_html(self, html_content: str) -> Optional[Webpage]:
try:
response = openai.beta.chat.completions.parse(
model=self.model,
messages=[
{"role": "system", "content": "Parse HTML and return page components."},
{"role": "user", "content": html_content}
],
response_format=Webpage
)
return Webpage(**json.loads(response.choices[0].message.content))
except Exception as e:
print(f"API error: {e}")
return None
הגדרנו ממשק OpenAIClient שהוא מדבר עם OpenAI. חדי העין יוכלו לראות שני דברים מעניינים בפונקצייה המרכזית:
openai.beta.chat.completions.parse- בשונה מהדרך הרגילה שבה אנחנו קוראים למודלי השפה מבית OpenAI, הפעם נקרא דרךbeta.response_format=Webpage- נכריח את התשובה של המודל שיהיה מסוג האובייקטWebpageאותו הגדרנו.
שלב 4: עיבוד HTML והדפסת התוצאות #
def process_html_content(html_content: str):
client = OpenAIClient()
webpage = client.parse_html(html_content)
if webpage:
print(f"Title: {webpage.title}")
print("Paragraphs:", webpage.paragraphs)
print("Links:", webpage.links)
print("Images:", webpage.images)
בניתי פונקציה מסכמת, שבעצם תשתמש ב- OpenAIClient ותדפיס לנו את התוצאות. שימו לב לנוחות, האובייקט שאנחנו מקבלים בחזרה הוא נגיש, ונתייחס אליו כמו אובייקט pydantic לכל דבר.
שלב 5: הרצה! #
# Sample HTML content for demonstration
html_content = """
<html>
<title>Structured Outputs Demo</title>
<body>
<img src="test.gif"/>
<p>Hello world!</p>
</body>
</html>
"""
# Run the HTML processing
process_html_content(html_content)
הגדרתי במשתנה סביבה קובץ HTML לדוגמא, והכנסתי אותו לפונקציה המסכמת שלנו process_html_content. מה שנקבל בפלט:
Title: Structured Outputs Demo
Paragraphs: ['Hello world!']
Links: None
Images: ['test.gif']
מגניב נכון?
Format Generator #
לאחר מספר פרוייקטים שעשיתי עם Structured Output, הגעתי לצורך לעדכן את ChatGPT שיידע על השימושיות החדשה. לכן, ייצרתי Custom GPT בשם Format Generator שיעזור לייעל את תהליך העבודה עם Structued Output וגם על הדרך Function Callings.
מוזמנים לנסות! 🏋🏼♂️
הערכת התרגום #
קיימות שיטות רבות להשוואות בין טקסטים על מנת לאמוד את טיב מודל התרגום. מחיפוש זריז באינטרנט, אפשר לראות את המטריקות הבאות: BLEU, METEOR, DEMETR ועוד. החלטתי להשתמש בגישה מעט שונה, בלי ידיעה מה יהיו התוצאות.
ציר פעולה:
- בשלב הראשון, ניצור וקטור (מאמר שלי בנושא) שיתן ייצוג במרחב עבור כל משפט והתרגום שלו. ההשערה שלי היא שככול שמשפטים קרובים מבחינה סמנטית, כך התרגום יהיה טוב יותר.
- בשלב השני, נזהה שמות של מקומות ויישויות מתוך ההודעות. במידה ויש מקום שלא נמצא בתרגום, נוכל להגיד שהתרגום פחות מוצלח.
- בשלב השלישי, ניישם בפועל את ההשוואה הסמנטית והשוואת היישויות.
- בשלב הרביעי, נבצע אנליזה על התוצאות ונקבע מה השירות הטוב ביותר.
בסופו של דבר, יהיה לנו ציון עבור כל שירות (Google ו-GPTs) שיאמוד את טיב תוצאות התרגום. אני מזכיר, הודעות המקור הן בערבית ואנחנו מתרגמים לאנגלית ולעברית.
שלב ראשון: ייצוג וקטורי #
לכולנו ברור שהמשפטים ״הכדור הכחול התגלגל״ ו-״הכדור הירוק התגלגל״ קרובים מבחינה סמנטית. הבעיה היא, שאנחנו משווים בין משפטים בשפות שונות. זאת אומרת, שכחלק מתהליך אימון המודל, ה-Dataset צריך לכלול מגוון שפות.
לשם בדיקת מודלי ה-Embedding, לקחתי משפטים זהים בשפות שונות: “مرحبا بكم في عالم الترجمة الآلية.” ו-“Welcome to the world of machine translation”.
תחילה השתמשתי במודל text-embedding-3-small של OpenAI והקרבה הסמנטית של המשפטים יצא 55%, נמוך מדי ולא שמיש.
לאחר מכן, מצאתי את המודל distilbert-multilingual שאומן על בסיס כ-50 שפות שונות. בעזרת המודל הזה, הקרבה הסמנטית בין אותם המשפטים עמד על 97%.
מצאנו מודל מתאים להשוואה בין משפטים, ומה שבעצם עשיתי בשביל לסיים את החלק הזה זה להשוואות בין כל הודעות המקור והתרגומים שלהם בכל שירות שאנחנו מודדים. אוסיף שהוספתי תהליכי עיבוד על תוצאות מודלי ה-NER, אבל לא אכנס אליהם כחלק מפוסט זה.
שלב שני: זיהוי יישויות #
NER או בשמו המלא Named-entity recognition, הוא תהליך של זיהוי יישויות (מקומות, תאריכים שמות ועוד) מתוך טקסטים. נבצע NER על כל הודעות המקור והתרגומים שלהם, ונבדוק התאמה בין כל ישות. ישות חסרה או עודפת תפגע בציון הסופי של השירות.
עבור כל שפה השתמש במודל NER ייעודי. חששתי שהמדידה תיפגע עקב כך, אבל החלטתי לקחת הנחת יסוד שביצועי המודלים הללו יחסית קרובים.
NER באנגלית #
השתמשתי במודל flair/ner-english, דוגמא לקלט ופלט:
if __name__ == "__main__":
ner = EnglishNER()
text_en = """
George Washington went to Washington. He was the first president of the United States.
"""
combined_entities_en = ner.process_text(text_en)
print("Combined Entities:")
for entity in combined_entities_en:
print(entity)
Combined Entities:
{'entity': 'PER', 'score': 0.99, 'word': 'George Washington', 'start': 5, 'end': 22}
{'entity': 'LOC', 'score': 0.98, 'word': 'Washington', 'start': 31, 'end': 41}
{'entity': 'LOC', 'score': 0.99, 'word': 'United States', 'start': 77, 'end': 90}
NER בערבית #
השתמשתי במודל camelbert-msa-ner, דוגמא לקלט ופלט:
if __name__ == "__main__":
ner = ArabicNER()
text_ar = """
الملك سلمان بن عبد العزيز، الذي وُلد في الرياض عام 1935، هو ملك المملكة العربية السعودية منذ عام 2015.
"""
combined_entities_ar = ner.process_text(text_ar)
print("Combined Entities:")
for entity in combined_entities_ar:
print(entity)
Combined Entities:
{'entity': 'B-PERS', 'score': 0.99, 'index': 2, 'word': 'سلمان بن عبد العزيز', 'start': 11, 'end': 30}
{'entity': 'B-LOC', 'score': 0.99, 'index': 10, 'word': 'الرياض', 'start': 45, 'end': 51}
{'entity': 'B-LOC', 'score': 0.98, 'index': 17, 'word': 'المملكة العربية السعودية', 'start': 69, 'end': 93}
NER בעברית #
השתמשתי במודל avichr/heBERT_NER, דוגמא לקלט ופלט:
if __name__ == "__main__":
ner = HebrewNER()
text_he = """
יצחק רבין, שנולד בתל אביב בשנת 1922, היה ראש הממשלה של מדינת ישראל בין השנים 1974 ל-1977 ושוב בין 1992 ל-1995.
"""
combined_entities_he = ner.process_text(text_he)
print("Combined Entities:")
for entity in combined_entities_he:
print(entity)
Combined Entities:
{'entity': 'B_PERS', 'score': 0.98, 'index': 1, 'word': 'יצחק רבין', 'start': 5, 'end': 14}
{'entity': 'B_LOC', 'score': 0.86, 'index': 5, 'word': 'בתל אביב', 'start': 22, 'end': 30}
{'entity': 'B_DATE', 'score': 0.93, 'index': 8, 'word': '1922', 'start': 36, 'end': 40}
{'entity': 'B_ORG', 'score': 0.78, 'index': 14, 'word': 'מדינת ישראל', 'start': 60, 'end': 71}
{'entity': 'B_DATE', 'score': 0.91, 'index': 18, 'word': '1974', 'start': 82, 'end': 86}
{'entity': 'B_DATE', 'score': 0.73, 'index': 20, 'word': '- 1977', 'start': 88, 'end': 93}
{'entity': 'B_DATE', 'score': 0.90, 'index': 24, 'word': '1992', 'start': 103, 'end': 107}
{'entity': 'B_DATE', 'score': 0.71, 'index': 26, 'word': '- 1995', 'start': 109, 'end': 114}
עבור כל שפה וישות, קיבלנו ציון שאומר כמה המודל בטוח בחיזוי שלו, יחד עם המיקום של הישויות במשפט וסוגם. שימו לב שבעברית יש לנו תאריכים, אבל בהשוואות התעלמתי מהם.
שלב שלישי: הרצה #
עכשיו שיש לנו דרך למדוד קרבה סמנטית בין שני משפטים, ולזהות התאמה ביישויות בין שני משפטים בשפות שונות, נשאר לנו להריץ את ה-Evaluation Pipeline שבנינו.
יש לנו שלושה שירותים שאנחנו מודדים את התרגום שלהם לשתי שפות. בעצם יש לנו שני מדידות עבור כל שירות. מטה הוספתי מדידה אחת עבור GPT-4o:
{
"Row 0": {
"gpt-4o - Arabic to Hebrew Evaluation": {
"reference": "الأرصاد الجوية تتوقع هطول أمطار غزيرة في مدينة جدة غدًا",
"candidate": "השירות המטאורולוגי צופה גשמים כבדים בעיר ג'דה מחר",
"entity_comparison": {
"missing": [],
"extra": [],
"matching": [["جدة", "בעיר ג׳דה"]]
},
"semantic_similarity": 0.9624,
"ner_match_score": 1.0,
"final_score": 0.9624,
"has_entities": true
},
"gpt-4o - Arabic to English Evaluation": {
"reference": "الأرصاد الجوية تتوقع هطول أمطار غزيرة في مدينة جدة غدًا",
"candidate": "The meteorological service expects heavy rainfall in the city of Jeddah tomorrow",
"entity_comparison": {
"missing": [],
"extra": [],
"matching": [["جدة", "Jeddah"]]
},
"semantic_similarity": 0.9573,
"ner_match_score": 1.0,
"final_score": 0.9573,
"has_entities": true
}
}
}
מה אנחנו רואים פה?
reference- הודעת המקור בערבית.candidate- התרגום באנגלית או עברית.entity_comparison- מערך של מערכים שמסווגים האם היישויות נמצאות או לא בתרגום.semantic_similarity- קרבה סמנטית בין המשפטים.ner_match_score- ציון NER, מושפע מכמות היישויות החסרות או עודפות.final_score- ציון סופי.has_entities- אינדיקציה לקיום NER, למול כך שיש משפטים שאין להם יישויות.
שלב רביעי: אנליזה #
בשלב האחרון, נעבור על גרפים שונים שבניתי, שיעזרו לנו להחליט את השורה התחתונה; מה הדרך הטובה ביותר לתרגם?
התפלגות ציוני NER #
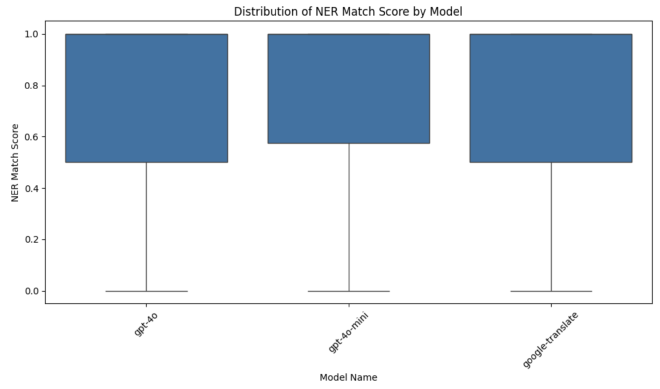
בבדיקה של ציון התאמת NER, אפשר לראות שהתפלגות שלושת השירותים קרובה, מה שמראה שאיכות תרגום היישויות זהה יחסית. אפשר לראות שיש ציונים שמגיעים גם ל-0, אבל למול כך שההתנהגות הזאת נמצאת גם בשירות של גוגל, הייתי אומר שביצועי השירותים זהה בהיבט תרגום יישויות.
התפלגות קרבה סמנטית #
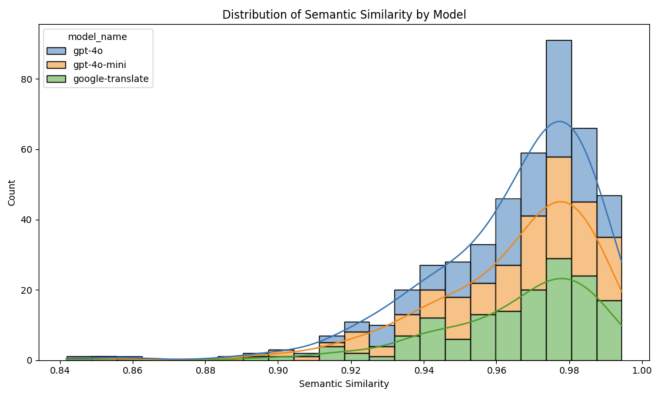
כל השירותים הגיעו לאחוזים גבוהים של קרבה סמנטית בין המשפט המקורי לתרגום, עם זאת אפשר לראות ש-GPT-4o הגיע לביצועים הגבוהים יותר, בזמן שביצועי Google Translate נפרסים ומעט נמוכים יותר.
השוואת תרגום לעברית יחסית לאנגלית #
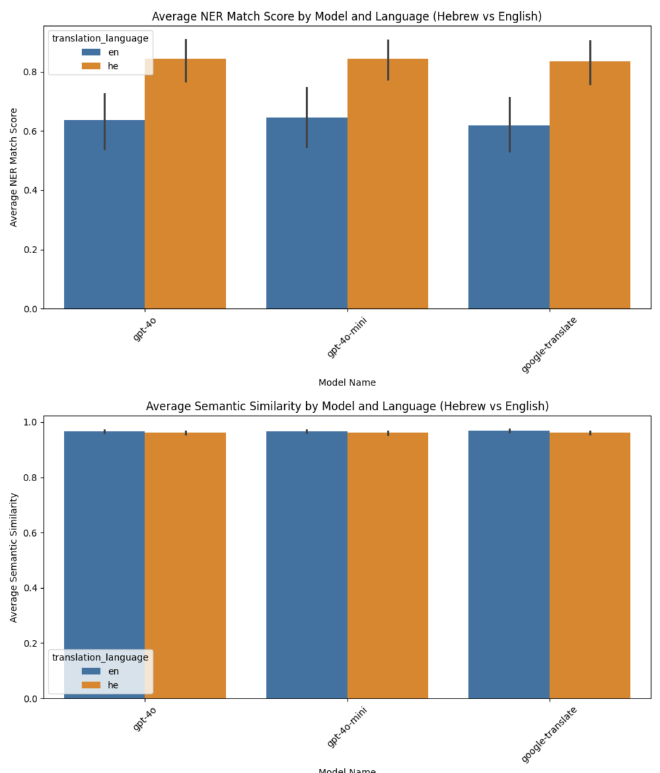
הגענו לשורה התחתונה, איזה מודל היה טוב יותר. אפשר לראות שמבחינת NER, שלושת השירותים התקשו לתרגם לאנגלית, אבל הצליחו יחסית לתרגם לעברית. ההשערה שלי, היא שעברית וערבית שפות שמיות וקרובות יותר מאשר אנגלית, ולכן זאת הייתה התוצאה.
מבחינה סמנטית, אין הבדל משמעותי בין עברית לאנגלית.
סיכום #
מתוך הבדיקות שביצעתי, לא קיים הבדל משמעותי ועמוק בין ביצועי מודלי השפה ו-Google Translate, ועל כן בפועל ב-Production השתמשנו בתרגום של GPT-4o mini למקרי הצורך. הודות למחקר זה, הורדנו משמעותית את הצורך הכללי בתרגום, והמחקר הזה תרם לי רבות בתחום ניתור תוצאות מודלי שפה.
מקווה שאהבתם, אשמח לשמוע פידבק והצעות לשיפור Evaluation של תרגום.
נתראה במאמר הבא!