המתמלל האוטומטי 🤖

מכירים את זה שאתם מקבלים הקלטה, ואין לכם באמת כוח להקשיב לה? שהייתם שמחים שמישהו אחר היה עושה את זה? הכירו את Tekatzer, הבוט שמיועד בדיוק לכך. הבוט מקבל הקלטה, לא משנה מה אורכה, ואז מתמלל ומקצר אותה.
Data Pipeline #
Plan A #
כשיצאתי לדרך, חשבתי שמדובר על תהליך פשוט. משתמש שולח הודעה לבוט, הבוט קורא ל-Lambda, שמחזירה את התוצאה לבוט ואז ללקוח.
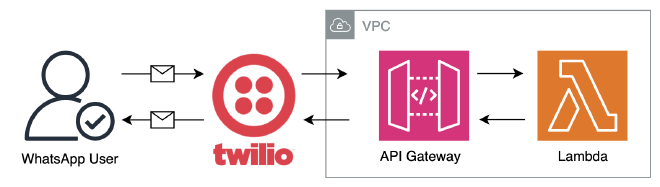
Plan B #
אחרי שמימשתי הכל ועבד פיקס על הקלטות קצרות שלי, ניסיתי לשלוח הקלטה של דקה. ואז נתקלתי ב-Timeout של Twilio, שעומד על 10 שניות ולא ניתן לשינוי. מפה אתם מבינים ששיניתי כל ה-Pipeline, שיעבוד ללא תלות באורך ההקלטה.
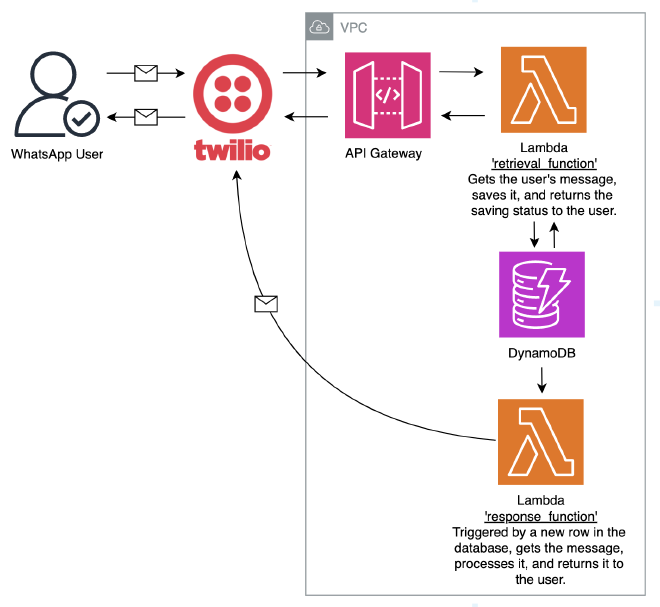
כמו שאתם יכולים לראות ליבת ה-Pipeline נשארה זהה, עם זאת הוספתי Trigger אוטומטי שקורא ל-Lambda חיצונית, ובכך אנחנו לא תלויים ב-Timeout של Twilio. כמה מילים על Twilio ונתחיל.
Twilio #
ליצר בוט ב-WhatsApp דורש התממשקות עם WhatsApp. ל-Meta יש API ייעודי, אבל החלטתי לעבוד עם Twilio, אשר לטענתם מנגישה את WhatsApp. בדיעבד ייתכן שהייתי עובד ישר עם ה-API הרשמי.
WhatsApp Sandbox #
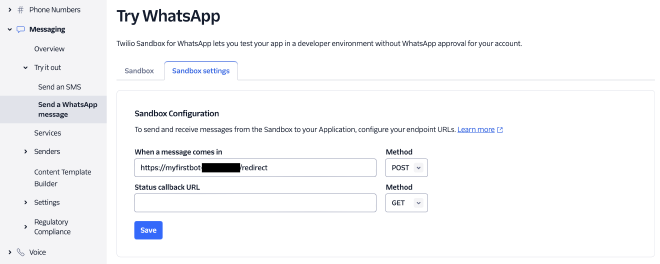
הממשק של Twilio פשוט ובסיסי. בתוך ה-WhatsApp Sandbox נוכל להגדיר מספר, שבכל פעם שהודעה מתקבלת אליו, ירוץ Webhook.
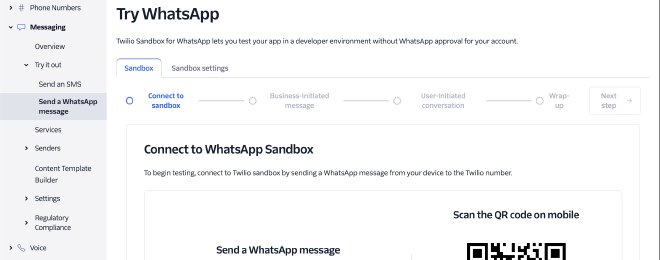
בהגדרות של המספר שלנו נוכל להגדיר שבכל פעם שהודעה מתקבלת, Endpoint נקרא אוטומטית. השתמשתי ב-Twilio Functions שהוא מובנה באתר שלהם, קראתי לפונקציה redirect/.
Functions and Assets #
השלב הבא הוא לייצר את redirect/. נעבור על כל שלב בקוד. אני מזכיר, המטרה של הפונקציה הזו היא לקרוא ל-AWS Gateway API על מנת להכניס את ההודעה החדשה ל-DynamoDB, ולהחזיר למשתמש סטטוס במידה והצלחנו לשמור או לא.
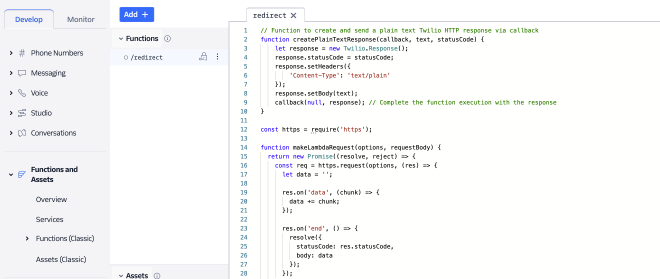
הקוד שכתבנו מכיל פונקציה ראשית ו-2 פונקציות עזר.
exports.handler היא הפונקציה הראשית. היא אחראית על קבלת תשובה ושליחתה ל-Lamdba על מנת שנשמור אותה. היא מקבלת context שמכיל את המפתחות, event שמכיל את הפרטים של ההודעה, ו-callback שמכיל הפניה לתשובה. הפונקציה אוטפת את ההודעה שקיבלנו ב-requestBody, קוראת ל-AWS Gateway דרך הפונקציה makeLambdaRequest, מקבלת כתשובה האם הצלחנו לשמור את ההודעה או ומחזירה למשתמש את הסטטוס בעזרת הפונקציה createPlainTextResponse.
exports.handler = async function(context, event, callback) {
const apiUrl = new URL(context.endpoint_url);
const voiceRecordingUrl = event.MediaUrl0;
const textMessage = event.Body;
const fromNumber = event.From;
const toNumber = event.To;
let requestBody = JSON.stringify({
voiceRecordingUrl: voiceRecordingUrl,
textMessage: textMessage,
fromNumber: fromNumber,
toNumber: toNumber,
});
console.log("Sending Body to Lambda: ", requestBody);
const options = {
hostname: apiUrl.hostname,
path: apiUrl.pathname,
method: 'POST',
headers: {
'x-api-key': context.lambda_key,
'Content-Type': 'application/json',
'Content-Length': Buffer.byteLength(requestBody)
}
};
try {
// Await the Lambda request and get the response
const lambdaResponse = await makeLambdaRequest(options, requestBody);
console.log("Lambda response received:", lambdaResponse);
// Use the Lambda response to inform your Twilio response
let responseMessage = "Request processed.";
if (lambdaResponse.statusCode === 200) {
responseMessage += " Success.";
} else {
responseMessage += " There was an error.";
}
createPlainTextResponse(callback, responseMessage, 200);
} catch (error) {
console.error("Error invoking Lambda:", error);
createPlainTextResponse(callback, "Error invoking Lambda function.", 500);
}
};
הפונקציה createPlainTextResponse מחזירה ללקוח הודעה.
// Function to create and send a plain text Twilio HTTP response via callback
function createPlainTextResponse(callback, text, statusCode) {
let response = new Twilio.Response();
response.statusCode = statusCode;
response.setHeaders({
'Content-Type': 'text/plain'
});
response.setBody(text);
callback(null, response); // Complete the function execution with the response
}
הפונקציה makeLambdaRequest קוראת ל-Lambda. בפועל היא קוראת ל-API Gateway הוא עושה את הקריאה ל-Lambda.
const https = require('https');
function makeLambdaRequest(options, requestBody) {
return new Promise((resolve, reject) => {
const req = https.request(options, (res) => {
let data = '';
res.on('data', (chunk) => {
data += chunk;
});
res.on('end', () => {
resolve({
statusCode: res.statusCode,
body: data
});
});
});
req.on('error', (error) => {
reject(error);
});
req.write(requestBody);
req.end();
});
}
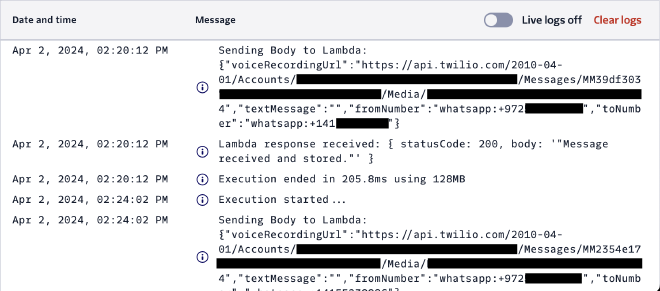
ב-Twilio Functions קיימת אפשרות ל-Live logs. במידה ונדליק את המצב הזה, נוכל לראות את ההודעות והשתלשלות האירועים בזמן אמת. זה מאוד נוח בזמן פיתוח.
Terraform #
אני עובד עם AWS Console עוד מהתיכון. מעולם זה לא היה נוח, לא הממשק משתמש ולא היכולת לשכפל סביבות. רציתי למנף את הפרוייקט הזה ולבנות את התשתית בעזרת Terraform תשתיות, בגישת infrastructure as code. השתמשתי ב-CLI שלהם על מנת להריץ את הקובץ. שימו לב שצריך להזדהות ל-AWS על מנת שנוכל ליצר תשתיות וקשרים בינם. אני ממליץ לא לתת הרשאות Admin, אלא לדייק אותן.
AWS Provider #
Terraform תומכת במגוון שירותי ענן, ולכן נגדיר שהענן שלנו הוא AWS. אני אוהב לעבוד ב-Resion הראשי שלהם, בלי להסתבך עם שירותים שלא קיימים בישראל.
# Configure the AWS provider
provider "aws" {
region = "us-east-1"
}
Lambda Functions #
אחד הדברים שאני נמנע זה לשים את המפתחות לשירותי SaaS בקוד. בעזרת variable נוכל לגשת אליהם. צריך לשים לב לשמור אותם בסביבה, לדוגמא: "export TF_VAR_OPENAI_API_KEY="your_openai_api_key_here.
# ============ Lambda Functions ============
# Define environment variables for the Lambda function
variable "TWILIO_ACCOUNT_SID" {}
variable "TWILIO_AUTH_TOKEN" {}
variable "OPENAI_API_KEY" {}
נגדיר IAM Role עבור ה-Lambda, שהוא ההרשאות שיהיו לפונקציות. ה-Role ייקרא assume_role_policy.
# Define the IAM role for the Lambda function
resource "aws_iam_role" "lambda_role" {
name = "lambda_execution_role"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Action = "sts:AssumeRole",
Principal = { Service = "lambda.amazonaws.com" },
Effect = "Allow",
Sid = "",
}],
})
}
עבור assume_role_policy, נגדיר שתהיה לו גישה מלאה לשירותים השונים: AWSLambda_FullAccess עבור יצירת Lambda ולעבוד איתה, AWSLambdaBasicExecutionRole עבור ביצוע Logging, ו-AmazonDynamoDBFullAccess עבור חיבור למסד הנתונים DynamoDB.
# Attach policies to the Lambda role
resource "aws_iam_role_policy_attachment" "lambda_full_access" {
role = aws_iam_role.lambda_role.name
policy_arn = "arn:aws:iam::aws:policy/AWSLambda_FullAccess"
}
resource "aws_iam_role_policy_attachment" "lambda_basic_execution_role" {
role = aws_iam_role.lambda_role.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
resource "aws_iam_role_policy_attachment" "dynamodb_full_access" {
role = aws_iam_role.lambda_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess"
}
על מנת לעבד הקלטות ולבצע קריאות HTTP, נצטרך להוסיף לסביבה שלנו ספריות שלא מובנות ב-Python. בשביל זה, נצטרך ליצר Layer שמכילה את הספריות השונות. בשביל להעלות ספריות, נצטרך ליצר קובץ zip שמכיל תיקיות בפורמט קבוע:
./lambda-layer/
└── python/
└── lib/
└── python3.8/
└── site-packages/
├── urllib3/
├── pydub/
└── requests/
לשם כך יצרתי קובץ requirements.txt שמציין את הספריות שצריך להוריד. לאחר מכן נוודא שבמידה והתיקיה הזו קיימת אז היא ריקה, ונתקין את הספריות הנדרשות. לאחר מכן ניצור python-dependencies-layer.zip שמכיל את כל הספריות אותם נרצה לעלות ל-Layer.
# Define the path to the requirements.txt file
REQ_PATH="./requirements.txt"
TARGET_DIR="./lambda-layer/python/lib/python3.8/site-packages/"
# Step 1: Check if requirements.txt exists in the lambda_function directory
if [ ! -f "$REQ_PATH" ]; then
echo "requirements.txt not found in the retrieval_function directory."
exit 1
fi
# Step 2: Clean the target directory if it already exists
if [ -d "$TARGET_DIR" ]; then
echo "Cleaning existing target directory: $TARGET_DIR"
rm -rf "$TARGET_DIR"
fi
# Recreate the directory structure for the Lambda layer
mkdir -p "$TARGET_DIR"
# Step 3: Install packages from requirements.txt into the target directory
pip3 install -r "$REQ_PATH" -t "$TARGET_DIR"
# Step 4: Navigate to the lambda-layer directory and zip the contents
cd lambda-layer
zip -r ../python-dependencies-layer.zip .
נחזור לקובץ Terraform שלנו, בו נגדיר python_dependencies_layer שמכילה את הקובץ python-dependencies-layer.zip שהכנו הרגע.
# Define a Lambda layer for Python dependencies
resource "aws_lambda_layer_version" "python_dependencies_layer" {
filename = "./python-dependencies-layer.zip"
layer_name = "python_dependencies_layer"
compatible_runtimes = ["python3.8"]
description = "Lambda layer with pydub and requests"
}
חשוב לי להוסיף, שספריית pydub צריכה גם את ffmpeg על מנת לעבוד. על מנת להוסיף אותה לקוד השתמשתי ב-Layer מוכנה שמצאתי ב-AWS Serverless Application Repository.
Retrieval Lambda #
על מנת להעלות את ה-Lambda, נצטרך לדחוס את הקוד שלה ל-zip. זה מה שאנחנו עושים עכשיו.
# Package the Lambda function code into a ZIP archive
data "archive_file" "retrieval_lambda_zip" {
type = "zip"
source_dir = "${path.module}/retrieval_function" # Directory path
output_path = "${path.module}/retrieval_function.zip"
}
נגדיר את ה-Lambda הראשונה שלנו, שמקבלת הודעה מ-Twilio ושומרת אותה ב-Dynamodb. הקוד יחסית ברור, אנחנו מגדירים את השם של הפונקציה, מה ה-handler (שזה הפונקציה הראשית), גרסת ה-Python ו-timeout. בנוסף, הוספנו את ה-Layers שהגדרנו קודם לכן. הוספנו ל-environment את המפתחות שלנו על מנת שנוכל להעלות אותם לסביבה.
# Create the Lambda function
resource "aws_lambda_function" "retrieval_lambda" {
function_name = "RetrievalFunction"
handler = "index.handler"
role = aws_iam_role.lambda_role.arn
runtime = "python3.8" # Adjust the runtime as necessary
filename = data.archive_file.retrieval_lambda_zip.output_path
source_code_hash = filebase64sha256(data.archive_file.retrieval_lambda_zip.output_path)
timeout = 60 # Set the timeout to 60 seconds (1 minute)
layers = [
"arn:aws:lambda:us-east-1:022438919154:layer:ffmpeg:1", # ffmpeg layer
aws_lambda_layer_version.python_dependencies_layer.arn # dependencies layer
]
environment {
variables = {
TWILIO_ACCOUNT_SID = var.TWILIO_ACCOUNT_SID
TWILIO_AUTH_TOKEN = var.TWILIO_AUTH_TOKEN
OPENAI_API_KEY = var.OPENAI_API_KEY
}
}
}
Response Lambda #
לשם הפשטות, התשתית של הפונקציה הראשונה ששומרת הודעות והפונקציה השניה שמעבדת אותן זהות, רק עם שמות שונים.
DynamoDB #
נגדיר טבלה חדשה בשם MessagesTable, שתהיה Serverless בעזרת הגדרת PAY_PER_REQUEST. המפתח יהיה MessageID.
# ============ DynamoDB Table ============
# Create a DynamoDB table to store messages
resource "aws_dynamodb_table" "messages_table" {
name = "MessagesTable"
billing_mode = "PAY_PER_REQUEST" # Or you can use PROVISIONED for provisioned throughput
hash_key = "MessageID"
attribute {
name = "MessageID"
type = "S" # S for String, N for Number, B for Binary
}
stream_enabled = true
stream_view_type = "NEW_IMAGE" # Options are: KEYS_ONLY, NEW_IMAGE, OLD_IMAGE, NEW_AND_OLD_IMAGES
tags = {
Environment = "dev"
}
}
אחרי שיש לנו טבלה, נגדיר Trigger שיקרא ל-response_lambda בכל פעם שמוכנסת רשומה חדשה לטבלה.
# Define an event source mapping to trigger the Lambda function from the DynamoDB stream
resource "aws_lambda_event_source_mapping" "dynamodb_response_trigger" {
event_source_arn = aws_dynamodb_table.messages_table.stream_arn
function_name = aws_lambda_function.response_lambda.arn
starting_position = "LATEST"
}
API Gateway #
בשביל שיהיה לי קל לזכור כשאחזור לפרוייקט ולהשתמש בו כתבנית לפרוייקטים הבאים. נקרא ל-API בשם example_api, עם Resource בשם example. לאחר מכן נחבר את ה-Resource לפונקציה retrieval_lambda.
# ============ API Gateway ============
# Create an API Gateway REST API
resource "aws_api_gateway_rest_api" "example_api" {
name = "ExampleAPI"
description = "Example API integrated with Lambda"
}
# Define a resource for the API
resource "aws_api_gateway_resource" "example_resource" {
rest_api_id = aws_api_gateway_rest_api.example_api.id
parent_id = aws_api_gateway_rest_api.example_api.root_resource_id
path_part = "example"
}
# Define a method for the API resource
resource "aws_api_gateway_method" "example_method" {
rest_api_id = aws_api_gateway_rest_api.example_api.id
resource_id = aws_api_gateway_resource.example_resource.id
http_method = "POST"
authorization = "NONE"
api_key_required = true
}
# Integrate the API method with the Lambda function
resource "aws_api_gateway_integration" "lambda_integration" {
rest_api_id = aws_api_gateway_rest_api.example_api.id
resource_id = aws_api_gateway_resource.example_resource.id
integration_http_method = "POST"
http_method = "POST"
type = "AWS_PROXY"
uri = aws_lambda_function.retrieval_lambda.invoke_arn
depends_on = [aws_api_gateway_method.example_method]
}
נאפשר ל-API לקרוא ל-Lambda בעזרת AllowExecutionFromAPIGateway.
# Grant API Gateway permission to invoke the Lambda function
resource "aws_lambda_permission" "allow_apigateway" {
statement_id = "AllowExecutionFromAPIGateway"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.retrieval_lambda.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_api_gateway_rest_api.example_api.execution_arn}/*/*"
}
לאחר מכן נעלה לאוויר את ה-API שבנינו.
# Deploy the API Gateway
resource "aws_api_gateway_deployment" "example_deployment" {
depends_on = [
aws_api_gateway_integration.lambda_integration,
# aws_api_gateway_method.example_method
]
rest_api_id = aws_api_gateway_rest_api.example_api.id
stage_name = "v1"
triggers = {
redeployment = sha256(jsonencode(aws_api_gateway_rest_api.example_api.body))
}
lifecycle {
create_before_destroy = true
}
}
API Key and Usage Plan #
השלבים הבאים זה ליצר מפתח ל-API על מנת לעלות את סף האבטחה, אותו נחבר ל-Usage Plan. שימו לב שהמפתח וה-URL Endpoint ישארו זהים כל עוד לא מחקנו והתקנו את הסביבה מחדש.
# ============ API Key and Usage Plan ============
# Create an API key for accessing the API
resource "aws_api_gateway_api_key" "example_api_key" {
name = "example-api-key"
description = "API Key for accessing Example API"
enabled = true
}
# Create a usage plan for the API
resource "aws_api_gateway_usage_plan" "example_usage_plan" {
name = "example-usage-plan"
api_stages {
api_id = aws_api_gateway_rest_api.example_api.id
stage = aws_api_gateway_deployment.example_deployment.stage_name
}
}
# Associate the API key with the usage plan
resource "aws_api_gateway_usage_plan_key" "example_usage_plan_key" {
key_id = aws_api_gateway_api_key.example_api_key.id
key_type = "API_KEY"
usage_plan_id = aws_api_gateway_usage_plan.example_usage_plan.id
}
Python Code #
Retrieval Lambda #
הפונקציה Retrieval היא הראשונה שתהיה במגע עם הלקוח. המטרה שלה הוא לשמור את ההודעה שמקבלת לתוך טבלה - MessagesTable, ולהחזיר סטטוס שמירה ללקוח. נשמור בעזרת הפעולה put_item, ונבדוק האם השמירה בוצעה בהצלחה בעזרת ResponseMetadata ומחזירים בהתאם תשובה ללקוח.
import json
import uuid
import boto3
# Assuming you have configured DynamoDB access and the table is defined
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('MessagesTable')
def handler(event, context):
# Serialize the entire event
event_body = json.dumps(event)
# Store in DynamoDB
try:
response = table.put_item(
Item={
'MessageID': str(uuid.uuid4()),
'EventBody': event_body # Storing the entire event body
}
)
# Check if the operation was successful
if response.get('ResponseMetadata', {}).get('HTTPStatusCode') == 200:
status_message = 'Message received and stored successfully.'
else:
status_message = 'Failed to store message.'
except Exception as e:
# Handle potential errors
status_message = f'Error occurred: {str(e)}'
return {
'statusCode': 200 if 'successfully' in status_message else 500,
'body': json.dumps(status_message)
}
Response Lambda #
הפונקציה Response היא הפונקציה שעושה את כל ה-Heavy Lifting - מקבלת את ההקלטה, מעבדת אותה, ומחזירה תשובה מקוצרת ללקוח.
Imports and Dependencies #
import os
import json
import requests
from requests.auth import HTTPBasicAuth
from pydub import AudioSegment
from io import BytesIO
# Extract environment variables
twilio_sid = os.getenv('TWILIO_ACCOUNT_SID')
twilio_token = os.getenv('TWILIO_AUTH_TOKEN')
openai_key = os.getenv('OPENAI_API_KEY')
os- נועדת לממשק עם סביבת הריצה. נשתמש בה על מנת לקבל את המפתחות ל-APIs בשימוש.json- משמשת להמרת פורמטים של JSON (גם Encode וגם Decode).request- משתמשת אותנו ביצירת בקשות HTTP בצורה מאובטחת.pydub- דרכה נמיר בין פורמטי קבצי קול.BytesIO- בעזרה נוכל להתמודד עם קבצים בינרים, במקרה שלנו קול.- הוספתי את כל המפתחות שאנחנו נצטרך אותם בקוד, שהם המפתחות ל-Twilio ול-OpenAI.
Fetch MP3 from URL #
def fetch_mp3_from_url(url, twilio_sid, twilio_token):
"""Fetches an MP3 file from a given URL."""
response = requests.get(url, auth=(twilio_sid, twilio_token))
response.raise_for_status() # Checks for HTTP request errors
audio_ogg = AudioSegment.from_file(BytesIO(response.content), format="ogg")
mp3_audio = BytesIO()
audio_ogg.export(mp3_audio, format="mp3")
mp3_audio.seek(0)
return mp3_audio
מטרת פונקציה זו היא לקבל את תוכן ההקלטה ולהחזיר אותה כקובץ אודיו. הדרך של Twilio לשלוח הודעות מוקלטות הוא דרך URL, אז הדבר הראשון שאנחנו עושים זה לקבל את תוכנו, בעזרת המפתחות שלנו. קיבלנו קובץ ogg שהוא קובץ אודיו מוקטן מאוד. לצערנו Whisper לא תומך עדיין בפורמט כזה, ונצטרך להמיר אותו ל-MP3. מדובר על משימה שדורשת כוח חישוב, ולכן הגדרנו ל-Lambda הזו יחסית הרבה זיכרון (Memory).
Transcribe MP3 to Text #
def transcribe_mp3_to_text(mp3_audio, openai_key):
"""Transcribes MP3 audio to text using OpenAI's API."""
url = 'https://api.openai.com/v1/audio/transcriptions'
headers = {'Authorization': f'Bearer {openai_key}'}
files = {
'file': ('audio.mp3', mp3_audio, 'audio/mp3'),
'model': (None, 'whisper-1')
}
response = requests.post(url, headers=headers, files=files)
mp3_audio.close()
return response.text
אחרי שיש לנו את ההקלטה בפורמט מתאים, נקרא ל-whisper על מנת שיתמלל לנו אותה.
Get OpenAI Response #
def get_openai_response(user_input, openai_key):
system_prompt = """
Summarize the voice recording transcription from a messaging app, focusing on the most exciting or
significant updates as if you're recounting them to a friend. Capture the essence of the news or
updates, maintaining the speaker's original perspective and tone. The original recordings are
personal narratives, so ensure your summary reflects a first-person viewpoint.
Please adhere to the following guidelines:
- Directly Summarize: Provide a straightforward summary without introductions or conclusions. Jump
right into the main points as if continuing an ongoing conversation.
- Clear Language: The summary should be in Hebrew. Use English for any professional terms, ensuring
they are widely recognized or standard in the field being discussed. If a direct Hebrew translation
for a professional term is not commonly used or understood, keep the term in English.
- Simplicity and Accessibility: Aim for a summary that is easy to understand without accessing the
original recordings. Assume the listener has basic context but not detailed background information.
- Avoid Assumptions: Base your summary strictly on the content of the transcriptions. Do not fill
gaps with hypotheticals or assumptions about unmentioned details.
- Response Format: Present your summary in plain text, focusing on content clarity and ease of reading.
Your task is to distill the essence of the conversation into a compact summary that conveys the
critical updates or news, reflecting the speaker's own words and feelings. Remember, the goal is
to inform and engage, mirroring a natural, friendly update.
"""
url = "https://api.openai.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {openai_key}"
}
data = {
"model": "gpt-4-0125-preview",
"messages": [
{
"role": "system",
"content": system_prompt
},
{
"role": "user",
"content": f"Here is the transcription to summary: \n\n{user_input}"
}
]
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200:
response_data = response.json()
# Extracting the content of the response
content = response_data["choices"][0]["message"]["content"] if response_data["choices"] else "No content returned."
return content
else:
print(f"Error: {response.status_code}")
return f"Failed to get a response: {response.status_code}"
רציתי שיהיה מעניין, ולקצר את ההקלטה אחרי שתמללנו אותה. עשיתי Prompt יחסית ארוך, שמנסה להתאים בין נקודת המבט של שולח ההודעה לבין הסיכום הנכתב על ידי GPT-4. להמשך, הייתי מוסיף שכבה נוספת שבודקת את נקודת המבט של ההקלטה ולאחר מכן מסכם אותה בהינתן אותה נקודת המבט.
Send WhatsApp Message #
def send_whatsapp_message(twilio_sid, twilio_token, to_number, from_number, message_body):
"""Sends a WhatsApp message using Twilio's API."""
url = f'https://api.twilio.com/2010-04-01/Accounts/{twilio_sid}/Messages.json'
data = {
'To': to_number,
'From': from_number,
'Body': message_body
}
response = requests.post(url, data=data, auth=HTTPBasicAuth(twilio_sid, twilio_token))
return response
שליחת הודעת WhatsApp ללקוח. נשתמש בפונקציה הזו על מנת לעדכן את הלוקח שסיימנו לתמלל את ההודעה, ולאחר מכן את ההודעה המקוצרת עצמה.
Process Record #
def process_record(record):
"""Process a single record from the DynamoDB stream."""
if record['eventName'] == 'INSERT':
try:
new_image = record['dynamodb']['NewImage']
event_body = json.loads(new_image['EventBody']['S'])
message_details = json.loads(event_body['body'])
from_number = message_details['fromNumber']
to_number = message_details['toNumber']
message_content = message_details.get('voiceRecordingUrl') or message_details.get('textMessage', '')
if 'voiceRecordingUrl' in message_details:
mp3_audio = fetch_mp3_from_url(message_content, twilio_sid, twilio_token)
transcription = transcribe_mp3_to_text(mp3_audio, openai_key)
message_content = transcription
send_whatsapp_message(twilio_sid, twilio_token, from_number, to_number, "Message transcribed.")
# Use OpenAI for further message processing if needed
processed_message = get_openai_response(message_content, openai_key)
send_whatsapp_message(twilio_sid, twilio_token, from_number, to_number, processed_message)
except Exception as e:
print(f"Error processing record: {e}")
כאשר אנחנו מקבלים רשומה חדשה ל-Dynamodb, מתקיים Trigger אוטומטי, ואחרי זה פונקציה process_record נקראת. היא משתמשת בכל הפונקציות עזר עליהן דיברנו מקודם. ציר הזמן:
- בדיקה שאכן מדובר על הכנסת רשומה ולא על שינוי אחר שבוצע בטבלה.
- קבלת תוכן הרשומה החדשה.
- תמלול ההקלטה לטקסט.
- קיצור הטקסט.
- החזרת תשובה ללקוח.
Lambda Handler #
def handler(event, context):
print("Received event:", event)
for record in event['Records']:
process_record(record)
return {'statusCode': 200, 'body': json.dumps({'message': 'Response processed successfully'})}
קריאה אחת של ה-Lambda יכולה להכיל מספר רשומות של הודעה, ולכן לפני שנקרא ל-process_record נעשה לולאה על גבי כל הרשומות שהתקבלו.
סיכום #
בעזרת פרוייקט זה למדתי איך אפשר לרתום את יכולות עיבוד השפה של מודלי שפה לשימוש יום יומי, ליעול תהליכים ונוחות. הבשורה הגדולה מהחוויה שלי מהפרוייקט הזה הייתה השימוש ב-Terraform, שתרם למהירות הביצוע ולנוחות העבודה מול AWS.