להשוות בין מסדי נתונים כמו נינג'ה 🥷

יש לנו מסד נתונים, אנחנו מכירים אותו מ-א׳ ועד ת׳, הוא עקבי וקריא. יש לנו עוד מסד נתונים, עקבי אי-אפשר להגיד עליו; העמודה הראשית כתובה ידנית. המשימה: לנתח את שני מסדי הנתונים יחד. מוכר לכם?
אז לי כן, ואפילו מקרוב. כחלק מהשירות הצבאי שלי השוואתי בין מסד נתונים אחיד, לבין מסד נתונים שנכתב בכתב יד. איך עשיתי את זה אתם שואלים? בעשרות שעות של עבודה ידנית. החסרונות המרכזיים בעבודה בשיטה כזו:
זמן עבודה יקר, שהיינו מעדיפים להשקיע בדברים אחרים. יתר על כן, זמן העבודה עלולה להביא לשחיקה, משהו שבוודאי לא נרצה להגיע.
זמן העבודה גורר להגדלת טווח הטעות, ובכך המידע עלול להיות פחות אמין ממה שהוא גם ככה.
חזרתיות לא אפשרית, ובכל פעם נצטרך לסווג מחדש. לא כיף בכלל.
אחרי קריאת מאמר זה תוכלו לדעת איך נוכל לעשות את התהליך הזה בצורה אוטומטית, בשלבים:
- צעדים ראשונים 👣
- הכרת מסדי הנתונים 🔎
- הלחמת עמודות 🔗
- ניתוח מסקנות 🤔
- זה רק ההתחלה 😎
צעדים ראשונים 👣 #
ספריות #
לפני שאתחיל, השתמשתי ב-Jupyter כ-IDE שלי בהרצה מקומית.
import pandas as pd
pd.set_option('display.float_format', lambda x: '%.3f' % x)
import numpy as np
from fuzzywuzzy import process
import matplotlib.pyplot as plt
import seaborn as sns
pandas(שורות 1-2) - נשתמש בה לניתוח נתונים בשפתPython. בשורה השנייה הגדרתי שאוכל לראות מספרים גדולים וקטנים מאוד בלי שסביבת הפיתוח תעגל.numpy(שורה 4) - ספריה אשר משמשת כאבן יסוד לרוב המוחלט של הספריות בתחום.Pandasאפילו בנויה עליה.fuzzywuzzy(שורה 6) - הספריה שתשמש אותנו בשוואות בין העמודות.matplotlibו-seaborn(שורות 8-9) - ספריות ליצירת גרפים.
מקור מסדי הנתונים #
כתבה זו התבססה על מאגר המידע הממשלתי Data Gov. כאחד שאוהב דאטא, האתר הזה ממש החלום של כל Data Analyst. תוכלו למצוא נתונים במגוון נושאים: כלכלת ישראל, תחבורה, בריאות וכו׳.
החלטתי לבדוק על האם יש קשר בין מספר סניפי הבנקים יחסית למספר התושבים בערי ישראל.
הכרת מסדי הנתונים 🔎 #
הורדתי את מסדי הנתונים בצורה ידנית למחשב ואז העלתי את קבצי ה-CSV בעזרת Python. למען האמת Data Gov תומכים ב-API, אבל במקרה הזה החלטתי ללכת על פשוט.
בנקים #
למסד הנתונים של הבנקים לא הייתה לי בעיה לגשת, בקטע קוד הבא ייבאתי את קובץ ה-CSV המקומי והדפסתי את שמות העמודות.
snifim = pd.read_csv('snifim_he.csv')
snifim.columns
👇🏼
Index(['Bank_Code', 'Bank_Name', 'Branch_Code', 'Branch_Name',
'Branch_Address', 'City', 'Zip_Code', 'POB', 'Telephone', 'Fax',
'Free_Tel', 'Handicap_Access', 'day_closed', 'Branch_Type', 'Open_Date',
'Close_Date', 'Merge_Bank', 'Merge_Branch', 'X_Coordinate',
'Y_Coordinate', 'ban_city', 'final_city'],
dtype='object')
במסד נתונים זה נשתמש בעיקר בעמודות Bank_Nameו-City.
אוכלוסיות #
במידה ונעיף מבט ב-CSV של נתוני מספר התושבים לכל ישוב, נוכל לראות הטקסט לא קריא, העמודות לא מסודרות. יש לנו בעיה.

הגעתי למסקנה שגם המחשב וגם ה-IDE צריכים לדעת מפורשות מה הקידוד הנדרש לקרוא את הקובץ. לאחר מחקר, הגעתי למסקנה שהקידוד הרלוונטי הוא ISO-8859-8.
population = pd.read_csv('residents_in_israel_by_communities_and_age_groups.csv',encoding='ISO-8859-8')
population = population.applymap(lambda x: x.strip() if isinstance(x, str) else x)
population.columns
👇🏼
Index(['סמל_ישוב', 'שם_ישוב', 'סמל_נפה', 'נפה', 'קוד_לשכת_מנא', 'לשכת_מנא',
'קוד_מועצה_אזורית', 'מועצה_אזורית', 'סהכ', 'גיל_0_5', 'גיל_6_18',
'גיל_19_45', 'גיל_46_55', 'גיל_56_64', 'גיל_65_פלוס'],
dtype='object')
קריאת
population(שורה 1) - נשתמש באותה הפונקציה כמו שקראנו את מסד הנתונים של סניפי הבנקים, אלא שהפעם נגדיר במשתנהencodingאת הקידודISO-8859-8.עריכת
population(שורה 2) - נוריד רווחים מיותרים בעזרת פונקציהstrip.
במסד נתונים זה נשתמש בעיקר בעמודות שם_ישוב' ו-סהכ
מחקר ראשוני 🧠 #
בנקים #
למעט לעשות ()snifim.head חשבתי שיהיה נחמד להציג את 10 חברות הבנקים הגדולות בארץ.
תחילה עשיתי פונקציה יחסית פשוטה שממיינת את ה-df ומחזירה את num_of_rows לפי הגודל.
def shorten_df(df, iterate_row, num_of_rows, comment):
sum_df = df[iterate_row].value_counts(ascending=True)
length = len(sum_df)
top_rows = sum_df[num_of_rows:].sort_values(ascending = False)
if num_of_rows < length:
other_rows = sum_df[:length - num_of_rows]
remaining_row = pd.Series(other_rows.sum(), index=[comment])
rows_plot = pd.concat([top_rows, remaining_row])
return rows_plot
return sum_df
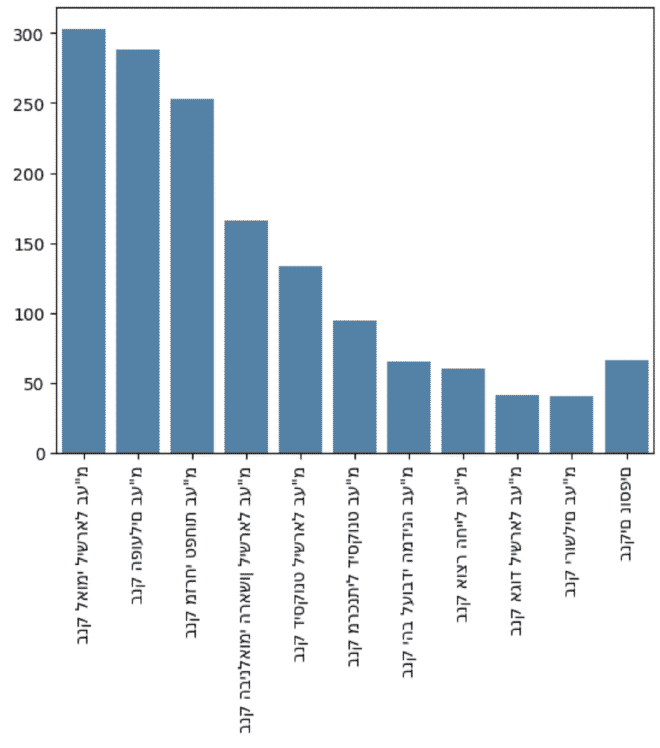
לאחר מכן יכלתי בקלות לראות את 10 חברות הבנקים הגדולות בארץ ולהציג גרף:
banks = shorten_df(snifim, 'Bank_Name', 10, 'בנקים נוספים')
ax = sns.barplot(x = banks.index, y = banks.values)
ax.set_xticklabels(ax.get_xticklabels(),rotation = 90)
plt.show()
אומנם הצלחנו להציג את הסניפים בגרף כמו שרציתי, אבל נתקלתי בבעיית הצגת עברית שעד כה לא הצלחתי לפתור אותה. אם מישהו מכיר פתרון, אשמח לדעת 😧.
לפני שנעבור למסד הנתונים של האוכלוסיות, החלטתי לבדוק כמה ערים ייחודיות יש במסד נתונים זה:
ban_cities = set(snifim['City'])
print("Banks unique cities: {0}".format(len(ban_cities)))
👇🏼
"Banks unique cities: 161"
אוכלוסיות #
על נתוני האוכלוסיות החלטתי לעשות groupby בסיסי על מנת לראות את סדרי הגודל ולהבין האם הנתונים הגיוניים:
population.groupby('שם_ישוב')['סהכ'].sum().sort_values()
👇🏼
כפר עבודה 1
ידידה 2
כרי דשא 3
איתנים 4
אורנים 5
...
ראשון לציון 277915
פתח תקווה 278645
חיפה 331402
תל אביב - יפו 573660
ירושלים 1056097
Name: סהכ, Length: 1264, dtype: int64
גם פה בדקתי כמה ערים ייחודיות יש במסד נתונים זה, שימו לב את ההבדל!
pop_cities = set(population['שם_ישוב'])
print("Population unique cities: {0}".format(len(pop_cities)))
👇🏼
"Population unique cities: 1264"
הלחמת עמודות 🔗 #
איפה הבעיה? #
בשני מסדי הנתונים יש לנו עמודה שמתייחסת לעיר, הבעיה היא שאופן כתיבת שמות הערים לא זהות. לדוגמא, נוכל לראות שהעיר “נהריה” כתובה במסד הנתונים של הבנקים עם שתי אותיות יוד, ובמסד הנתונים של האכולוסיה יוד אחת 🤬.
'נהרייה' in ban_cities 👉🏼 True
'נהריה' in pop_cities 👉🏼 True
אלגורתם Levenshtein Distance #
כחלק מהלימודים שלי במסלול Data Scientist with Python באתר Datacamp נתקלתי באלגוריתם זה לראשונה. בנוסף להסבר שלי, אני ממליץ בחום ללמוד את הרקע המתמטי במאמר Medium הזה.
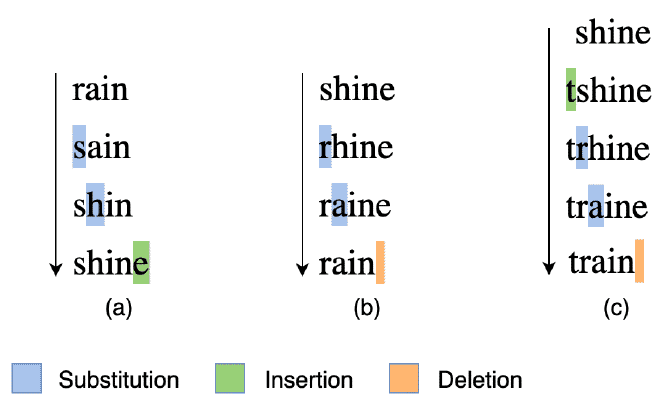
בהינתן שני str, נקבל מספר אשר מייצג המרחק בינם. מה זה מרחק אתם שואלים? כמות הפעולות הבאות שנצטרך לבצע בשביל להגיע בין str אחד לשני:
- הוספת תו 🧩
- מחיקת תו ⌫
- החלפת תו 🔄
אז איך נחשב את המרחק? #
בעזרת הפונקציה process אשר ייבאנו יחד עם ספריית fuzzywuzzy נוכל לחשב מרחק בין מילים. לשם הדוגמא (הועתק מ-Datacamp), נרצה למצוא את התא במערך strOptions שהכי קרוב ל-str2Match:
str2Match = "apple inc"
strOptions = ("Apple Inc.", "apple park", "apple incorporated", "iphone")
Ratios = process.extract(str2Match,strOptions)
print(Ratios)
👇🏼
[('Apple Inc.', 100), ('apple incorporated', 90), ('apple park', 67), ('iphone', 30)]
קיבלנו מערך, שמכיל בצורה מסודרת את ערכי מערך strOptions ואת המרחק היחסי ל-str2Match. זהו! עכשיו אנחנו יכולים לחזור למשימה שלנו ולהשוות בין ערי מסד הנתונים 🥳.
חישוב מרחק בין שמות ערים #
נשאר החלק הכי כיף, ליישם את אלגורתם המרחק על מסדי הנתונים. החלטתי להשוות בין מסד הבנקים לתושבים על פי איטואיציה ועל פי הפרשי כמות הערים.
ban_and_pop_city = pd.DataFrame(columns=['ban_city', 'pop_city', 'ratio'])
for ban_city in ban_cities:
Ratios = process.extract(ban_city,pop_cities)[0]
city_row = {
'ban_city': ban_city,
'pop_city': Ratios[0],
'ratio': Ratios[1]
}
city_row = pd.DataFrame(city_row, index=[0])
ban_and_pop_city = pd.concat([ban_and_pop_city, city_row], ignore_index = True)
ban_and_pop_city(שורה 1) - יצירתdfריק בו נכניס את שמות הערים במסד הבנקים והעיר המתאימה במסד התושבים.for ban_city(שורה 3) - לולאה שעוברת אחר שמות הערים במסד הבנקים.process.extract(שורה 4) - חישוב שם העיר ממסד התושבים הקרובה ל-ban_city.city_row(שורות 6-11) - יצירת שורה חדשה של עיר שנוכל להכניס ל-ban_and_pop_cityממקודם.pd.concat(שורה 13) - הכנסתcity_rowל-ban_and_pop_city.
איך אחוז ההתאמה מתפלג? #
היה לי חשוב להסתכל במבט על איך ההתאמה מתפרסת, בייחוד איפה.
sns.histplot(data=ban_and_pop_city, x="ratio", bins=20)
plt.show()
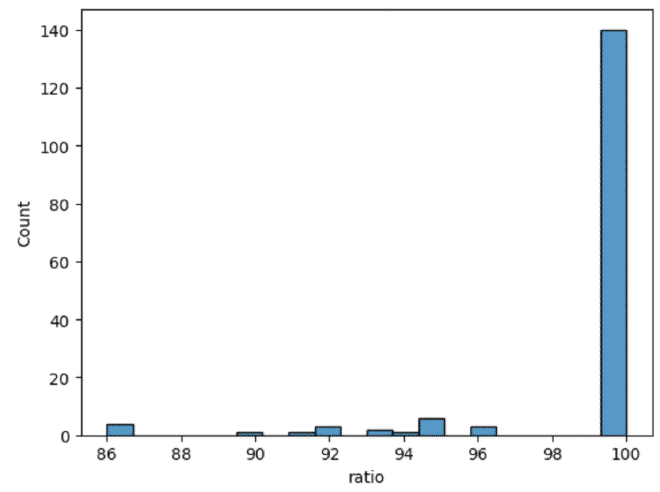
מצבנו טוב, רוב הערים ב-100 אחוז התאמה, אבל המשימה הבאה שלנו; להבין מי הערים שלא?
אז באילו ערים רמת התאמה נמוכה? #
במבט מהיר, אפשר לראות כי רוב הפערים נובעים כמו בדוגמא בהתחלה, ערים שכתובות עם שתי אותיות יוד או אחת. נחקור באילו שמות ערים לא היו שתי אותיות יוד ולא היה התאמה מלאה:
without_youd = ban_and_pop_city[ban_and_pop_city['ratio'] < 100]
without_youd = without_youd[~without_youd['ban_city'].str.contains('יי')]
| index | ban_city | pop_city | ratio |
|---|---|---|---|
| 73 | קרית תעופה | קרית יערים(מוסד) | 86 |
| 109 | נמל תעופה בן-גוריון | כרם בן זמרה | 86 |
| 131 | תל אביב -יפו | תל אביב - יפו | 96 |
| 139 | הערבה מ"א 54 | כאוכב אבו אל-היג’א | 86 |
| 140 | הר הנגב הצפוני מ"א 48 | הר גילה | 86 |
| 153 | אזור רמלה של"ש | רמלה | 90 |
שינויים ידניים #
כמו שנוכל לראות מהטבלה מעלה, ישנם מקרי קצה שנצטרך לערוך ידנית. לא ביטלנו בצורה מלאה את העבודה הידנית, אלא עברנו משיטה של עבודה ידנית לבדיקה במבט ציפור, ובכך חסכנו את רוב שעות העבודה.
city_df = ban_and_pop_city
city_df['final_city'] = city_df['pop_city']
city_df.loc[city_df['ban_city'] == 'נמל תעופה בן-גוריון', 'final_city'] = 'לוד'
city_df[city_df['pop_city'].str.contains('נמל תעופה בן-גוריון')]
city_df(שורה 1-2) - יצרנו העתק ל-ban_and_pop_cityשיהיה המילון שלנו. עמודתfinal_cityתכיל את השם הסופי של הערים.city_df.loc(שורה 4) - נסנן בצורה ידנית את שמות הערים אותם נרצה לשנות. לדוגמא, בנק בנמל התעופה שבהתחלה סווג בעיר כרם בן זמרה נסווג לעיר לוד.contains(שורה 6) - נבדוק את השינויים שעשינו.
איחוד הטבלאות 😲 #
עכשיו שיש לנו מילון (city_df), נוכל להשתמש בו בהמרת שמות הערים בטבלה snifim כך שנוכל לחבר לטבלת population:
בטבלת population #
population = population.merge(
city_df[['pop_city','final_city']],
left_on='שם_ישוב',
right_on='pop_city',
how='left'
)
בטבלת snifim #
snifim = snifim.merge(
city_df[['ban_city', 'final_city']],
left_on = 'City',
right_on = 'ban_city',
how = 'left'
)
ניתוח מסקנות 🤔 #
באילו ערים אין בנקים? #
החלטתי לפני הכל להבין מה אחוז הערים בהן יש לפחות בנק אחד:
population['has_bank'] = np.where(population['final_city'].isnull(), False, True)
length = len(population['final_city'])
no_banks = (population['has_bank'] == False).sum()
print("Percentage of cities with banks: {0:.0%}".format((length - no_banks) / length))
👇🏼
"Percentage of cities with banks: 13%"
has_bank(שורה 1) - במידה ופעולת המיזוג החזירהnull, נוכל להבין שאין בנק באותה העיר. הערך הוא בוליאני באותה עמודה.length(שורה 2) - מייצג את כמות הערים יש לנו בטבלת האוכלוסיות.no_banks(שורה 3) - סוכם את מספר הערים בהן אין בנקים.
87% מישובי ישראל ללא סניף בנק אחד לפחות. מפתיע, נכון? בואו נציג את זה בגרף:
pop_no_banks = population[population['has_bank'] == False]
sns.histplot(data=pop_no_banks, x="סהכ")
plt.axvline(x=pop_no_banks['סהכ'].median(), color='red')
plt.show()
pop_no_banks(שורה 1) - הוספתיdfלשם הפשטות, שיכיל את פרטי הערים בהן אין סניפי בנק.sns.histplot(שורה 3) - הצגתי את התפלגות כמות התושבים כפונקציה של כמות הישובים.plt.axvline(שורה 4) - הצגתי את החציון בגרף.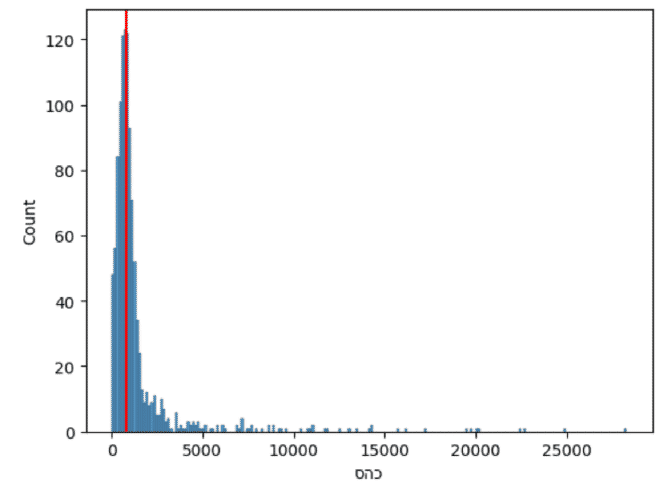
התפלגות ערים בינוניות-גדולות ללא סניף #
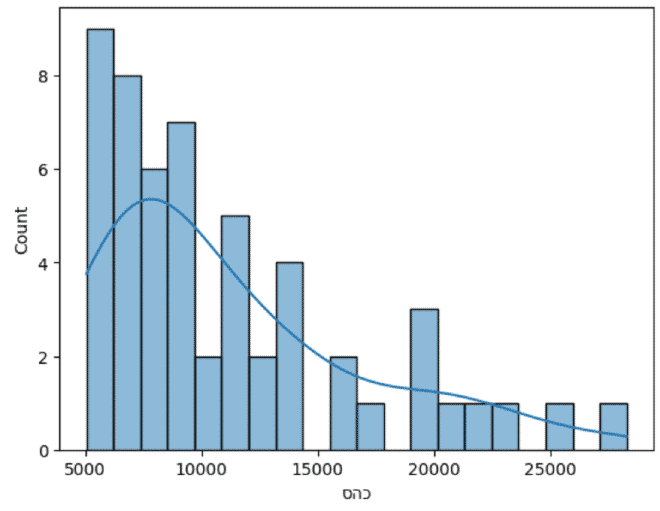
כמו שאנחנו יכולים להבין מהגרף מעלה, מאוד הגיוני שיישובים עד 5000 תושבים לא יהיה בהם סניפי בנק. החלטתי לבחון את התפלגות הערים בהן אין סניפי בנק ובהם יותר מ-5,000 תושבים.
sns.histplot(
data=pop_no_banks[pop_no_banks['סהכ'] > 5000],
x="סהכ",
bins = 20,
kde = True
)
התפלגות קבוצות הערים #
השלב הבא שעניין אותי היה לעשות השוואה בין ההתפלגויות הערים ללא סניפי בנק למול ערים בהן יש.
plt.xlim(0, 1000)
ax = sns.histplot(population, x="סהכ", hue="has_bank")
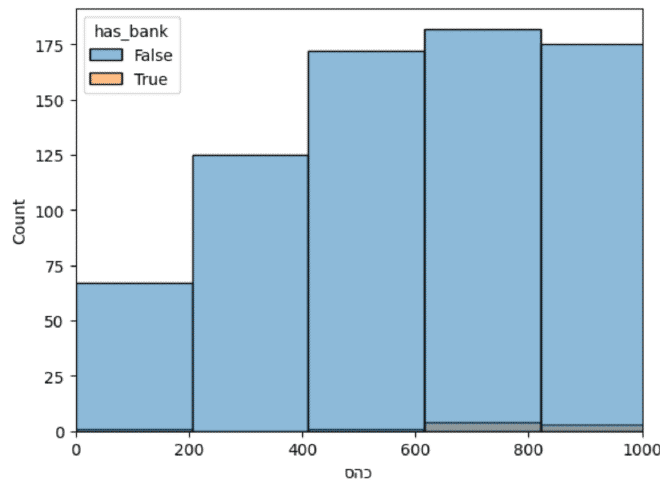
עשינו היסטוגרמה פשוטה כמו בחלק הקודם, אבל נתקלנו בבעיה: סדרי גודל שונים בין הקבוצות.
תהליך Data Binning #
מה זה בכלל? #
בשביל שנוכל להשוות ולהסתכל על התפלגות הקבוצות נצטרך לחלק את הקבוצות בצורה שווה. לשם כך נשתמש בתהליך שנקרא Binning. התהליך מחלק את הערכים לטווחים זהים, ומשייך כל ערך לטווח הרלוונטי. נחשיב את התהליך כ-Data Preprocessing.
חלוקת הערכים #
pop_bind = population.copy()
min_val = 2500
max_val = 75000
num_bins = 30
bins = np.linspace(
min_val,
max_val,
num_bins
)
pop_bind['b_pop_y'] = pd.cut(pop_bind[pop_bind['has_bank']]['סהכ'], bins=bins, include_lowest=True, precision=0)
pop_bind['b_pop_n'] = pd.cut(pop_bind[~pop_bind['has_bank']]['סהכ'], bins=bins, include_lowest=True, precision=0)
pop_bind(שורה 1) - יצרתי שכפול שלpopulationבכדי לא ״לכלכך״ ולשמור על המידע נקי.- משתני טווח (שורות 2-3) - משתנים שיעזרו לנו להחליט מה הטווח של סך האוכלוסייה לכל עיר שנרצה לחלק.
num_bins(שורה 4) - מאחסן את כמות החלקים נרצה לחלק את המידע.np.linspace(שורות 6-10) - פונקציה שלNumpy, מקבלת טווח ערכים ואת מספר החלקים שנרצה לחלק. הפונקציה מחזירה מערךbinsשמכיל את הערך הגבוה באותו הטווח. לדוגמא; 2,500 ולאחריו 5,000 וכו׳.pd.cut(שורות 12-13) - פונקציה שלPandasשמחלקת ערכים על פיbins:- לכל שורה בטבלה, הפונקציה לוקחת את הערך (
סהכ) ובודקת מה הטווח המתאים מתוךbins. לדוגמא, העיר בשורה 1,261, בה יש 33,299 תושבים, שוייכה לטווח (32500.0, 35000.0]. pandas._libs.interval.Interval- סוג הערך שנקבל מפונקצייתcut. עלפיו נוכל לדעת מה הטווח שה-סהכשייך.- את הפונקציה הרצתי בנפרד לכל ערים עם בנקים ולערים בלי, כך שאוכל להשוות בינם בהמשך.
- לכל שורה בטבלה, הפונקציה לוקחת את הערך (
איחוד העמודות #
על מנת שנוכל להשוות בין ההתפלוגות, השלב הבא הוא לאחד בין עמודת b_pop_y לבין עמודת b_pop_n.
pop_bind['b_pop'] = pop_bind['b_pop_y'].fillna(pop_bind['b_pop_n'])
הכנה לקראת הצגה #
השלב הבא היה להכין טבלה מסכמת to_plot, שסוכמת לכל קבוצה כמה ערים יש.
to_plot = pop_bind.groupby(['b_pop','has_bank'])['סהכ'].count().reset_index()
| b_pop | has_bank | סהכ | |
|---|---|---|---|
| 0 | (2499.0, 5000.0] | False | 57 |
| 1 | (2499.0, 5000.0] | True | 6 |
| 2 | (5000.0, 7500.0] | False | 18 |
| 3 | (5000.0, 7500.0] | True | 8 |
| 4 | (7500.0, 10000.0] | False | 12 |
| 5 | (7500.0, 10000.0] | True | 10 |
הצגה #
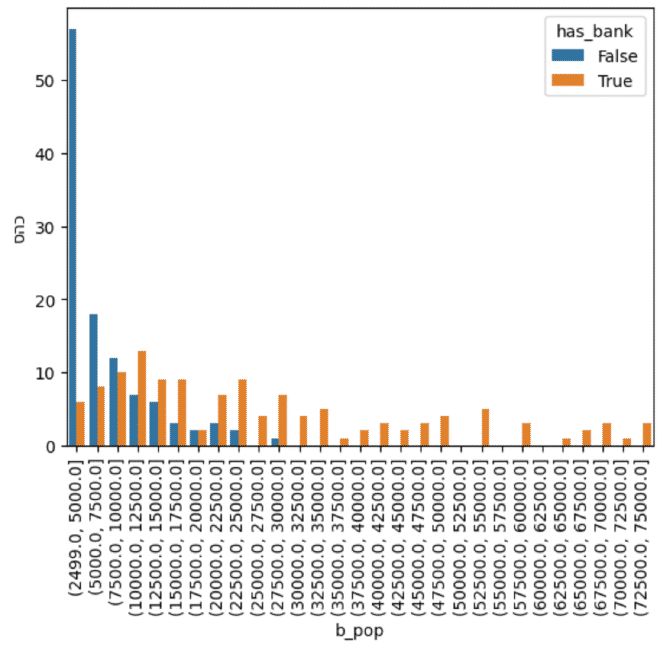
עכשיו בעזרת פונקציית barplot יחסית פשוטה נוכל להשוות בצורה מוחשית את ריכוז הערים עם סניפי בנק יחסית לערים ללא.
sns.barplot(x = 'b_pop',
y = 'סהכ',
data = to_plot,
hue = 'has_bank')
plt.xticks(rotation=90)
plt.show()
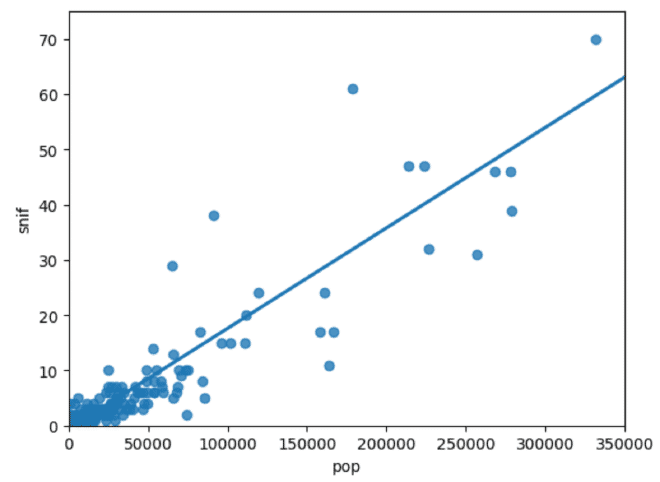
הקשר בין סך סניפי הבנקים לבין לאוכלוסייה #
עניין אותי לבדוק האם קיים קשר בין סך סניפי הבנקים לבין מספר התושבים בכל ישוב.
snif = snifim.value_counts('final_city')
pop = population.groupby('שם_ישוב')['סהכ'].sum()
snif_pop = pd.concat([snif, pop], axis=1)
snif_pop.columns = ['snif', 'pop']
snif_pop = snif_pop[~snif_pop['snif'].isna()]
snif(שורה 1) - כמה סניפים בכל עיר.pop(שורה 2) - כמה תושבים בכל ישוב.snif_pop(שורות 4-5) - טבלה אחודה.isna(שורה 6) - הוצאתי ערים בהן אין בנקים.
plt.xlim(0, 350000)
plt.ylim(0, 75)
sns.regplot(x="pop",
y="snif",
data=snif_pop,
ci=None)
plt.show()
lim(שורות 1-2) - הגדרת טווח לציר x ולציר y. הוצאתי ערי קיצון, תל אביב וירושלים.sns.regplot(שורות 4-7) - יצירת scatterplot עם קו מגמה ליניארי שמציג את הקשר.
זוהי רק ההתחלה 😎 #
עכשיו אחרי שלמדנו מספר טכנולוגיות ייחודיות, נוכל להעמיק את תהליכי המחקר שלנו עוד מעבר, הרחבת מאגר המידע והצגתו בצורה שלא חשבנו עד כה.
הדבר החשוב ביותר שאני רוצה לסכם איתו, הוא לזכור לכל אורך המחקר מה המסר שאנחנו רוצים להעביר ומה בכלל אנחנו חוקרים, אחרת אנחנו נאבד את עצמנו ולא תהיה לנו שורה תחתונה ברורה.