זיהוי תמונה דרך CNN 📸

ראייה הוא חוש שאנחנו משתמשים בו מהרגע שאנחנו קמים עד הרגע שאנחנו הולכים לישון. אנחנו מבשלים, נוהגים, מזהים תחושות אצל האחר, עושים פעולות יום יום ועוד שלל פעולות שנמצאות בתת-מודע שלנו.
כשהתחילו לאמן רשתות לזיהוי פרצופים, הצליחו להסביר למחשב את המאפיינים של פרצופי בני האדם, והמחשב יכל להתחיל לזהות בין פרצופים, בין איברים על הפרצוף, תחושות ועוד. אותה הרשת נוירונים עמוקה (Deep Learning) מורכבת משני חלקים. התברר, שנוכל להחליף את החלק השני במשימות שאינן קשורות, לדוגמא איתור מחלה בתמונת איבר גוף, דרך אימון מחדש (Retraining) של החלק השני בלבד. בואו נעמיק ונלמד יחד.
אתם רואים את התמונה מעלה? מעניין נכון? נלמד מה היא מייצגת ואיך לבנות משהו כזה בעצמנו.
Convolutional Neural Networks #
הכנסת תמונה למודל #
למחשב, תמונה היא רק פיקסלים. לקחתי לדוגמא תמונת הנשיא ה-16 של ארצות הברית, אברהם לינקולן ועיבדתי אותה ב-Python. צמצמנו את קני המידה של התמונה, המרנו את הפיקסלים שלה ל-Grayscale כך שכל פיקסל יכיל ערך אחד בין 0 ל-255. התוצאה היא מטריצה דו-מימדית של מספרים שמייצגים בפועל את התמונה.

בפוסט Word2Vec למתחילים למדנו על מבנה של רשתות נוירונים. נוכל להמיר את המטריצה למערך, ולהכניס את אותו המערך לשכבת Input Layer של רשת נוירונים, ובכך על פניו פתרנו את הבעיה. אז מתברר שלא ממש; במעבר מתמונה דו-מימדית למערך חד-מימדי איבדנו את האפשרות להתמצות במרחב, וביצוע עיבוד תמונה כמו זיהוי פרצופים לא היה מתאפשר. בנוסף, אם עבור כל פיקסל יהיה לנו נוירון ייעודי שהוא יתחבר לכל נוירון ב-Hidden Layer, נגיע למודלים כבדים וגדולים; לאימון ולהרצה.
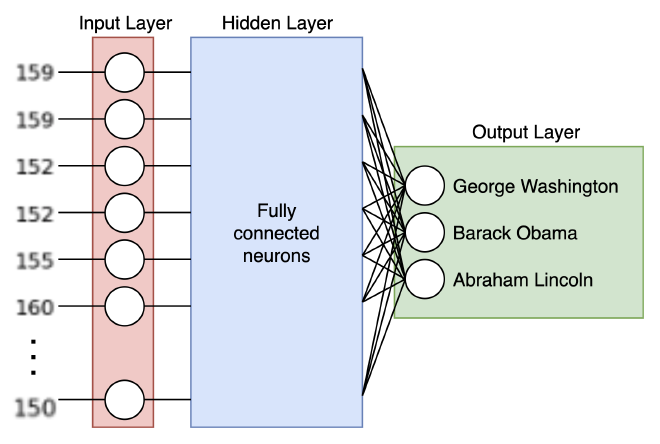
סקירת מודל CNN #
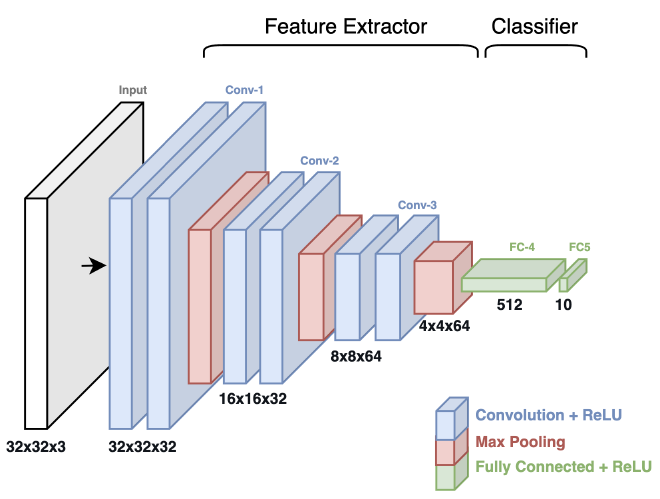
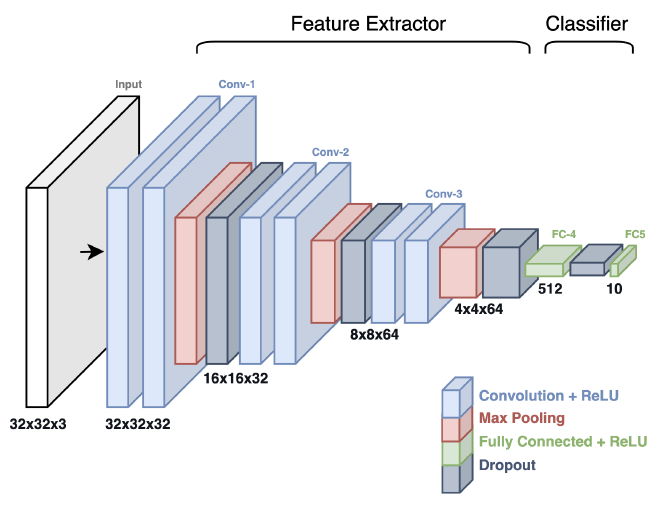
אחרי שהבנו מדוע הפתרון על בסיס הידע הנוכחי שיש לנו לא מתאים למשימה שנרצה לפתור, נלמד על CNN, קיצור של Convolutional Neural Network. על מנת להבין את מבנה המודל, את החישוב שמאפשר לו ראיה במרחב ואת המושגים השונים, נשתמש בדיאגרמה של מודל זיהוי התמונה VGG-16:
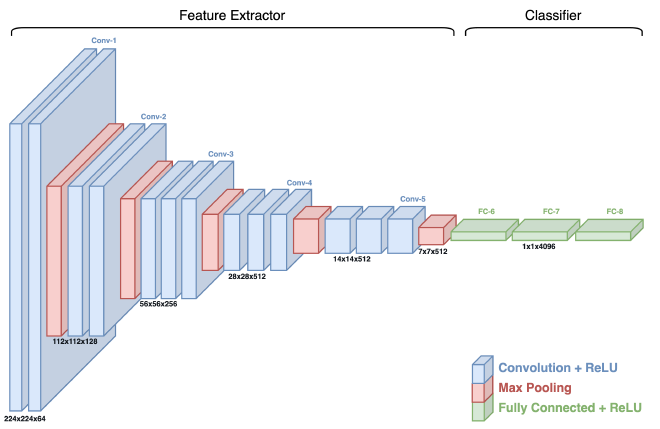
Feature Extractor (לעיתים נקרא Backbone או Body) - החלק שרואה את התמונה. אחראי לזיהוי התכונות (features) השונות; קווים, פינות, טקסטורות ועוד. ישנם סוגים שונים של שכבות שמאפשרות לו לבצע את פעולת זיקוק זו: convolution layers, pooling layers, וגם activation layers. חלק זה ממפה ומזקק את התכונות החשובות בתמונה שיעזרו לחלק השני של רשת ה-CNN.
Classifier (לעיתים נקרא Head) - לאחר שהתכונות השונות זוקקו, חלק זה של הרשת מטפל במשימה לה אימנו את המודל, לרוב סיווג אם התמונה מכילה אובייקט או לא. חלק זה מכיל בדרך כלל שכבות מרובת חיבורים (fully connected layers) שמטרתן לקבלת חיזוי לאובייקט המופיע בתמונה.
לכל שכבה יש Spatial Dimension (ציר X וציר Y) ו-Depth Dimension (עומק השכבה). לדוגמא, השכבה הראשונה היא בגודל 224 על 224 ובעומק של 64. ככול שאנחנו מתקדמים בתהליך עיבוד התמונה במודל, Spatial Dimension קטן בזמן ש-Depth Dimension גדל.
אכתוב בפשטות; יש לנו תמונה ופילטר (בדרך כלל מטריצה בגודל 3 על 3) נבחר אזור מתוך התמונה (באותו גודל הפילטר). על האזור נבצע פעולת Convolution Operation בינו לבין הפילטר. נשמור את תוצאת החישוב ונמשיך לזוז על פני כל התמונה. נוכל להגדיר חפיפה בין האזורים. אחרי שביצענו את אותה הפעולה על פני שטח כל התמונה, נעביר את התוצאה בפונקצית הפעלה, ובכך למודל יהיה האפשרות לייצג קשרים שלא לינוארים בלבד. חישוב זה מעניק למודל ראיה מרחבית. במודל יש לנו רצף של שכבות Conv שמבצעות את אותו החישוב ומזקקות דפוסים ייחודיים. לאחר מכן, יש לנו שכבות Fully Connected שמקבלות את הדפוסים ומבצעות את פעולת הזיהוי לשמו המודל אומן.
אחרי שהבנו במבט ציפור איך המודל עובד, נלמד יחד את אופן פעולת מרכיביו.
חלק 1 - Feature Extractor #
בכדי לאפשר למודל לזהות תכונות במרחב התמונה ולהפיק מכך תובנות, נשתמש בשיטה לה אני אוהב לקרוא ״ריצוף״. אנו בוחרים אזור מסוים (Patch) מהתמונה עבור כל נוירון בשכבת הקלט. נזיז (Slide) את האזור בצעדים קטנים מאורכו, ככה שתהיה חפיפה אחד של השני. באמצעות חלוקת התמונה לאזורים כאלו, אנחנו מצליחים לשמור על המידע המרחבי של התמונה ומאפשרים למודל לזקק מאפיינים ייחודיים ממנה. סריקת האזורים בשפה המקצועית נקרא “פיתול” (Convolution).
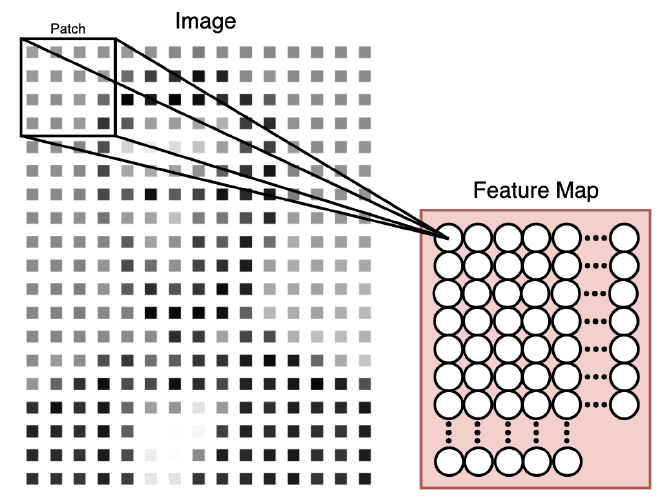
אם תסתכלו טוב, תוכלו לראות שהתמונה היא אותה התמונה של לינקולן מתחילת המאמר. בשונה מרשת נוירונים בשיטת ה-Fully Connected, כאן לכל נוירון ב-Input Layer יש אזור (Patch) של 4 פיקסלים שמשוייכים לו. הפיקסלים הללו הם נפרסים במרחב, והנוירון לא מוגבל לראייה חד-מימדית. אבל רגע, האיור יפה והלוגיקה ברורה, חוץ מהפרט הכי חשוב - איך בפועל מחשבים את הערך של כל נוירון?

Convolution Operation #
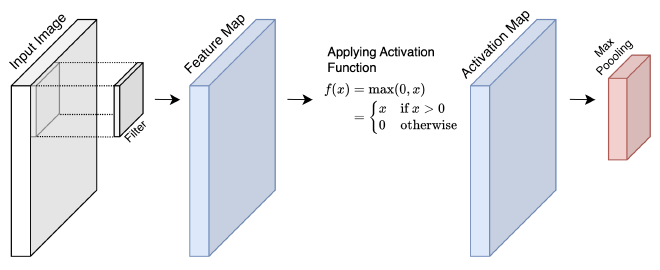
הכירו Convolution Operation שתשמש אותנו על מנת לזקק דפוסים ייחודיים בתמונות (באיור של מודל VGG-16 אלו הם השכבות הכחולות). ניקח לדוגמא תמונה ו-Filter בגודל 3 על 3 פיקסלים. אז מה הצעדים לחישוב פעולת Convolution?
- אזור: נגדיר אזור (Patch) אשר תוחם אזור בתמונה לו נרצה לעשות פעולת Convolution. ל-Patch שתי תכונות מרכזיות; גודל (Size) ה-Patch שלנו, וכמה פיקסלים ה-Patch יזוז (Stride) לאורך התמונה בכל פעם.
- הכפלה: עבור כל Patch בתמונה, נכפיל את הערך במיקום המתאים ב-Filter. פעולת ההכפלה הזו היא אבן הבניין של פעולת Convolution.
- סכימה: נסכום את תוצאות הכפלת 9 התאים של ה-Patch ב-9 התאים של ה-Filter נסכום יחד.
- פונקציית הפעלה: אחרי שהכפלנו וסכמנו, נעביר את הערך החדש בפונקציית הפעלה (בדומה לפוסט הקודם). ב-CNN פונקציית ההפעלה המקובלת היא ReLU (שהוא Rectified Linear Unit). פונקציה זו מאפשרת למודל ללמוד דפוסים מסובכים, בגלל שהיא לא ליניארית.
- הזזה: נבצע Sliding על כל ה-Patches בתמונה ככה שנחשב את ערך ה-Convolution בכל אזורי התמונה.
- ריכוז התוצאות: אחרי שביצענו פעולת Convolution על פני כל התמונה, קיבלנו Activation Map אותה נעביר לשכבות נוספות במודל (אם לא היינו מעבירים את הערך בפונקציית הפעלה, נקרא למטריצה Feature Map). לעיתים נרצה להוסיף Padding על מנת לא לאבד מגודל התמונה.
איירתי תמונה שתעזור לכם להבין איך החישוב עובד ברמה כללית:
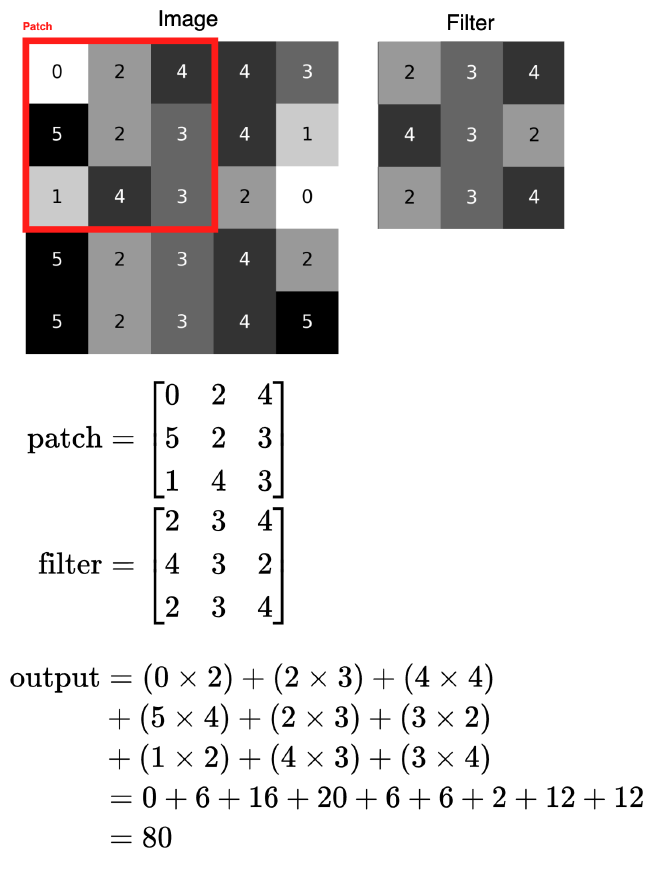
MNIST Convolution Visualizer #

לפני שאנחנו ממשיכים, הכירו את MNIST - אוסף תמונות של מספרים בכתב יד, שנוצר בשנת 1994. פיתחתי אתר שלוקח תמונה מה-Dataset, מציג אותה, ומבצע פעולת Convolution. טרם עידן ה-CNN, חוקרים מצאו מספר Filters שימושיים לעיבוד תמונות; לקחתי את הפופולריים והצגתי אותם באתר, כך שהמשתמשים יכולים לבחור איזה אחד להחיל על התמונה. באתר מוצג ערכי ה-Filter שנבחר על התמונה, ומאפשר למשתמשים לחקור ולהעמיק. מצרף לכם סרטון שתוכלו לראות את האתר בפעולה.
| שם פילטר | הסבר |
|---|---|
| Edge Detection | זיהוי הקצוות מזהה את קווי המתאר של אובייקטים בתמונה. הפילטר פועל בצורת זיהוי שוני צבע חד, התואם לקצוות. |
| Sharpen | פילטר חידוד שמגביר את הניגידיות בין פיקסל לפיקסלים הסמוכים אליו, שגורם להדגשת הקצוות. |
| GaussianBlur | פילטר טשטוש. כל פיקסל בתמונה מוחלף בממוצע המשוקלל של הפיקסלים הסמוכים לו. המשקל המדוייק מוגדר על ידי הפילטר. |
Pooling Layers #
ברוב מודלי ה-CNN נהוג שגודל השכבה (Spatial Dimension) קטן ככול שנכנסים עמוק יותר למודל, נוכל לראות את זה גם במודל VGG-16. גודל השכבה קטן בעזרת שכבות שנקראות Pooling Layers (באיור של מודל VGG-16 אלו הם השכבות האדומות), שבאות במודל לאחר מספר שכבות Conv. אומנם על פניו נראה שמדובר על שכבה בסיסית, אבל שכבת Pooling מפחיתה משמעותית את משקל המודל, שעוזר להמנעות מ-Overfitting וצמצום גודל המודל - דברים מהם נרצה להימנע.
איך שכבת Pooling עובדת? אסביר בעזרת דוגמא. ניקח תמונה בגודל 4 על 4, ונחלק אותה לאזורים (Stride) בגודל 2 על 2. עבור כל אזור, נבדוק איזה תא עם הערך המקסימלי. יש פה שני דברים שונים מ-Convolution Operator; אין חפיפה בין כל אזור, וה-filter ללא פרמטרים מאומנים, אלא רק פעולת Max פשוטה. אחרי פעולת Max Pooling, התוצאה תעבור לשכבה הבאה במודל.
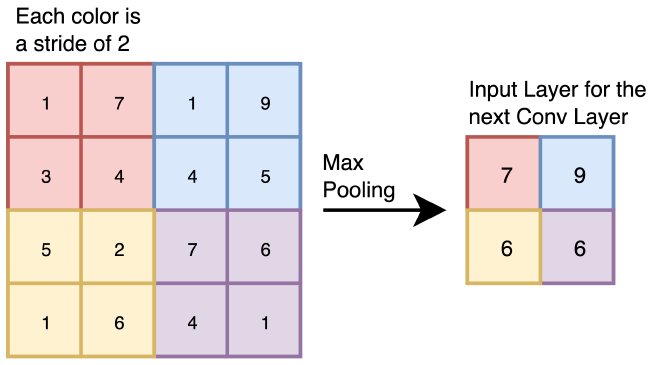
סיכום Feature Extractor #
לפני שנעבור לחלק השני של המודל, נסכם את החלק הראשון שלו, Feature Extractor. נקבל Input Image, במקרה שלנו בגודל 224 על 224. נבצע Convolutional Operator בעזרת Filter. את תוצאות נמקם ב-Feature Map, אותה נעביר דרך Activation Function על מנת לתת למודל את האפשרות לייצג יחס לא-ליניארי. לאחר מכן, נצמצם את גודל השכבה הבאה דרך שכבת Max Pooling. המטריצה שקיבלנו תוכנס כ-Input לשכבת Conv הבאה.
חלק 2 - Classifier #
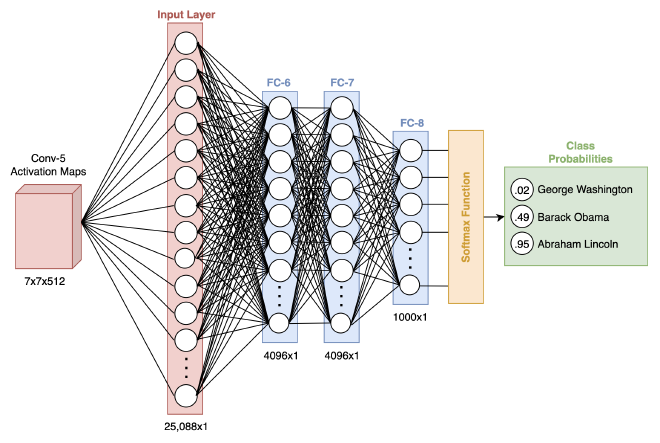
במודל VGG-16, שכבת ה-Conv החמישית והאחרונה מכילה Activation Map בגודל 7 על 7 על 512 (אחרי ביצוע Max Pooling). שכבה זו מכילה עיבודים שונים של התמונה, שלוקחים בחשבון את המרחב ופרמטרים רבים אותם המודל מאתר בתהליך אימונו. בעצם מה שנותר לנו לעשות הוא לקשר אותם העיבודים לבין ה-Labels אותם נרצה לזהות, באמצעות רשת נוירונים עמוקה.
לפני שתוצאת ה-Feature Extractor תוכל להיכנס ל-Classifier, נצטרך להמיר (Flatten) את המטריצה למערך חד-מימדי, במקרה שלנו בגודל 25,088, שישמש את ה-Classifier בתוך Input. חשוב להגיד שבתהליך ההמרה למערך חד-מימדי אנחנו עדיין שומרים על המאפיינים היחודיים שהמודל זיקק, ובכך לא נאבד אותם בדרך.
אחרי שיש לנו מערך חד-מימדי, נכניס את ערכיו לרשת נוירונים עמוקה בעלת שלוש שכבות. אחרי שהתמונה עוברת במודל נקבל מספרים, ללא טווח מוגדר ותחום. על מנת להפוך את המספרים לאחוזים, ננרמל אותם בעזרת פונקציית Softmax. הפונקציה לוקחת את המספר המקסימלי והמינימלי של השכבה האחרונה (FC-8), ומנרמלת אותם לטווח בין 0 ל-1, כאשר 1 מייצג רמת סבירות 100%.
מה יקרה עבור תמונות שונות? כל תמונה שתעבור את תהליך העיבוד בחלק הראשון של המודל, ה-Activation Map המתאים לה יהיה שונה. לאחר מכן, בעזרת רשת הנוירונים העמוקה, נוכל לזהות קשרים בין אותם ה-Maps ל-Labels. איך? כל נוירון ונוירון מכיל אוסף Weights, שערכם מתכווננים בזמן אימון המודל ומותאמים ל-Labels השונים. מה שמעניין הוא שאנחנו לא יודעים באמת להסביר את אותם הקשרים והמשקלים בנויורונים, אבל באותו הזמן אנחנו מצליחים בעזרתם להגיע לתוצאה הרצויה.
זיהוי אובייקטים בתמונה #
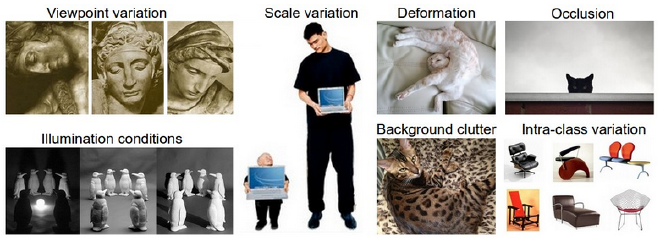
למרות שיש מספר סוגים, נתמקד במרכזי, Classification שמטרתו היא זיהוי אובייקטים בתמונה. במידה ונרצה לאמן מודל שיצטרך לזהות אובייקטים בתמונה, הוא יצטרך לזקק מאפיינים יחודיים בתמונות ב-Dataset שמצביעים על דפוסים ייחודיים לכל אובייקט, כך שיוכל להבדיל בינן. כמו שכולנו יודעים, כל אובייקט יכול להצטלם בצורה שונה; זווית צילום, כמות אור, מצלמה וכו׳. המודל שלנו יזקק את ה-Features המרכזיים בתמונות, עלפיהן הוא יוכל לזהות בין האובייקטים ללא תלות בשונות התמונות.
מימוש CNN ב-Python #
אחרי שלמדנו את מרכיבי מודלי CNN, את השכבות השונות ופעולות עיבוד התמונה שמתקיימים בו, הגיע השלב בו נממש מודל כזה בעצמנו. לא נממש מודל גדול כמו VGG-16, אלא מודל מוקטן יותר, שיהיה לנו נוח לאמן אותו על המחשב האישי.
יבוא ספריות #
כמו שאנחנו כבר יודעים ממדריכים קודמים, הצעד הראשון שאנחנו עושים לפני שאנחנו מתחילים לפתח הוא לייבא את הספריות הנדרשות לפיתוח.
כמו שאפשר לראות, אנחנו משתמשים עם ספריה איתה עדיין לא עבדנו בשם Tensorflow. ספריה זו הינה ספריית Open Source אשר חברת Google פיתחה. ספריה זו מאפשרת לנו להוריד את ה-Dataset של התמונות, להגדיר את מודל ה-CNN ולבצע עיבודים נוספים.
בנוסף, אנחנו משתמשים בספריית dataclass. ספריה זו מאפשרת לנו לשמור ערכים בתוך classes באמצעות decorator. נשתמש בתכונה זו על מנת ליצר משתנים גלובליים לשמירה על עקביות וסדר הקוד.
import os
import random
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from skimage.transform import resize
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Dropout, Flatten
from tensorflow.keras import models
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from matplotlib.ticker import (MultipleLocator, FormatStrFormatter)
from dataclasses import dataclass
from typing import List
אחרי שייבאנו את הספריות, נגדיר Seed. מה זה אומר? על מנת להגדיר את הבסיס של רשת הנוירונים, המשקלים מוגדרים בצורה אקראית. Seed מאפשר לנו לקבע את הערך הפסודו-אקראי (pseudorandom) ובכך לאפשר יצירת משקלים אקראיים, במקביל לשחזורם. זה מעניין אותנו כי כאשר נאמן מודלים, נרצה לוודא שאקראיות בסיס הרשת טרם אימונה לא משפיע על תוצאות החיזוי.
SEED_VALUE = 42
random.seed(SEED_VALUE)
np.random.seed(SEED_VALUE)
tf.random.set_seed(SEED_VALUE)
טעינת CIFAR-10 Dataset #
CIFAR-10 Dataset מכיל 60,000 תמונות של 10 classes שונים. נוכל לגשת אליו ישירות דרך ספריית Tensorflow בעזרת tensorflow.keras.datasets.
כמו שאתם יכולים לראות, יש לנו חלוקה של Train ו-Test, ככה שנוכל לעשות Validation למודל על מידע שהוא לא ראה בזמן האימון.
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
print(X_train.shape)
print(X_test.shape)
(50000, 32, 32, 3)
(10000, 32, 32, 3)
סקירת ה-Dataset #
לפני שנבנה את המודל ונתחיל לאמן אותו, חשוב להעיף מבט עליו. נעשה את זה בשני צעדים. לפני שנתחיל, ה-classes של ה-dataset מוגדרים כ-index בין 0 עד 9, ולכן תוכלו לראות ששמרתי בנפרד משתנה class_names דרכו נוכל לעשות את הקישור בין index לערך שלו בפועל.
בחינת התמונות #
התמונות של CIFAR-10 קטנות, רק 32 על 32 פיקסלים. יהיו תמונות שאפילו לנו יהיה קשה להבין מה יש בהן.
plt.figure(figsize=(18, 9))
num_rows = 4
num_cols = 8
# Class names for CIFAR-10
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
for i in range(num_rows*num_cols):
ax = plt.subplot(num_rows, num_cols, i + 1)
plt.imshow(X_train[i,:,:])
label_index = int(y_train[i])
ax.set_title(class_names[label_index])
plt.axis("off")

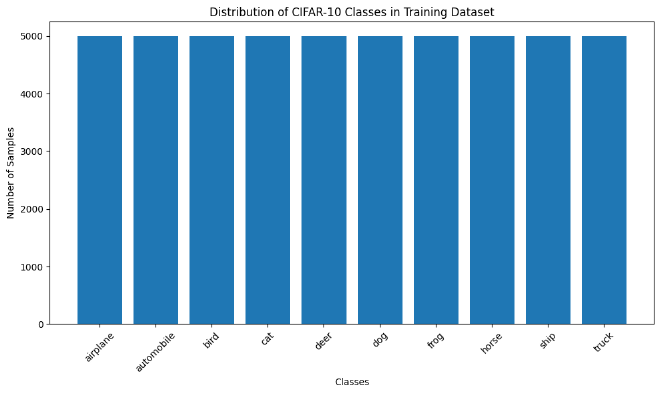
בחינת תדירות #
אחרי שהעפנו מבט על איך התמונות נראות בהיבט מהיר, חשוב לוודא שתדירות הופעת ה-classes זהות ואין לנו class עם הופעות גדולות יותר מ-class אחרת. מצב כזה ייצור סטייה למודל ואנחנו רוצים להימנע מכך. אפשר לראות שהתדירות של ה-classes קבועה ואין לנו חשש לסטיית המודל.
# Count the occurrences of each label in the training dataset
unique, counts = np.unique(y_train, return_counts=True)
# Plot histogram
plt.figure(figsize=(10,6))
plt.bar(class_names, counts)
plt.xlabel('Classes')
plt.ylabel('Number of Samples')
plt.title('Distribution of CIFAR-10 Classes in Training Dataset')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
הכנת ה-Dataset לקראת האימון #
נרמול הצבעים #
פיקסל מכיל שלושה ערכים: אדום, ירוק וכחול (RGB), כאשר כל ערך בין 1 ל-255. נצטרך לנרמל אותם, ככה שיכילו ערכים בין 0 ל-1. נעשה את זה דרך חלוקת הפיקסל ב-255. לדוגמא, פיקסל עם ערך 128 יומר לערך 0.502
נרמול עוזר לרשת הנוירונים לסיים את האימון מהר יותר, ומונע להיכנס ללולאת local optima.
# Normalize images to the range [0, 1].
X_train = X_train.astype("float32") / 255
X_test = X_test.astype("float32") / 255
קידוד #
One-hot encoding או בעברית קידוד, ממיר Labels לוקטור בינארי. בעזרת קידוד נוודא שהרשת לא בטעות מתייחסת לקטגוריה כמספר בו סדר הופעת המספרים חשובה (Ordinal Data).
לדוגמא, נניח שב-Dataset ה-Labels הם ‘airplane’, ‘automobile’, ו-‘bird’ מיוצגים כ-0, 1 ו-2 בהתאמה. ללא קידוד, ייתכן והמודל יחשוב ש-‘bird’ זה בעצם פעמיים ‘automobile’.
לקחתי לדוגמא את שלושת המילים והצגתי דוגמא לקידוד:
- ‘airplane ’ [1, 0, 0]
- ‘automobile ’ [0, 1, 0]
- ‘bird ’ [0, 0, 1]
# Change the labels from integer to categorical data.
print('Original (integer) label for the first training sample: ', y_train[0])
# Convert labels to one-hot encoding.
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print('After conversion to categorical one-hot encoded labels: ', y_train[0])
Original (integer) label for the first training sample: [6]
After conversion to categorical one-hot encoded labels: [0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
הגדרות #
לפני שאנחנו ניישם את המודל ונאמן אותו, נשאר לנו צעד אחרון. נגדיר פרמטרים מראש ככה שהם יהיו במקום מרוכז, ככה שבמידה ונרצה לכוון משהו נוכל לעשות את זה בלי להאבד בקוד.
בעזרת dataclasses נוכל לייצר DatasetConfig ,TrainingConfig ו-CompileConfig כ-Classes עם פרמטרים בהם נשתמש בזמן אימון המודל.
@dataclass(frozen=True)
class DatasetConfig:
NUM_CLASSES: int = 10
IMG_HEIGHT: int = 32
IMG_WIDTH: int = 32
NUM_CHANNELS: int = 3
@dataclass(frozen=True)
class TrainingConfig:
EPOCHS: int = 31
BATCH_SIZE: int = 256
LEARNING_RATE: float = 0.001
SPLIT: float = 0.3
@dataclass(frozen=True)
class CompileConfig:
OPTIMIZER: str = 'rmsprop'
LOSS: str = 'categorical_crossentropy'
METRICS: List[str] = ('accuracy',)
מימוש מודל CNN #
הגענו לחלק לו חיכינו, הגדרת מודל CNN ואימונו על CIRFAR-10 dataset. אלו הצעדים שניישם:
- יצירת מודל על פי שכבות Deep
- Compile המודל
- אימון המודל בעזרת
()model.fit
המבנה של מודל ה-CNN שאנחנו בונים בהשראת המודל VGG-16 בו עסקנו בתחילת המאמר. עם זאת, במודל שלנו יש פחות שכבות וגודל ה-Input משמעותית קטן יותר - על מנת שנוכל לאמן את המודל מקומית ולא נצטרך מחשב חזק יותר. המודל מכיל שלוש שכבות Conv אחריהן מיקמנו שתי שכבות Fully Connected.
שימו לב ששכבת ה-Input בגודל 32x32x3, זאת אומרת תמונה בגודל 32x32 עם 3 ערוצי צבעים (RGB), ובכך המודל שלנו לוקח בחשבון את כל הצבעים ולא מתעלם מהם.
שכבות Convolution #
- בבלוק הראשון, יש לנו שתי שכבות Conv עם 32 Filters, צמודים עם שכבת Max Pooling.
- הבלוק השני דומה, אבל עם 64 Filters.
- הבלוק השלישי זהה לשני.
בשלושת בלוקי ה-Conv גודל ה-Filters יהיה 3x3, נשתמש ב-Padding מסוג same - נדאג שהגודל נשאר קבוע ופונקציית ההפעלה תהיה ReLU.
שכבות Classifier #
- נשתמש בפונקציית
Flattenעל מנת ״לשטח״ את מטריצות ההפעלה בגודל 4x4x64 למערך חד-מימדי בגודל 1024. - נוסיף שכבת Fully Connected עם 512 נוירונים ופונקציית הפעלה ReLU כמו תמיד.
- לבסוף, שכבת Output עם 10 נוירונים. 10 נוירונים כי יש לנו 10 סוגים של אובייקים (Classes) בינם המודל צריך להבדיל.
כמו שאתם יודעים, כל המספרים והגדלים שציינתי הם Hyperparameters אותם נוכל לשנות ולווסט ככול שנאמן יותר פעמים את המודל ונדע מה הקומבינציה הטובה ביותר. עם זאת, אנחנו צריכים להיזהר מאימון-יתר על מנת שהמודל לא ייצג Overfit. אציין שיכולנו גם פה לייצר dataclass ייעודי ולצמצם את חזרתיות שורות הקוד, עם זאת בחרתי כחלק מהלמידה לכתוב את כל שכבות המודל, ככה שיהיה יותר ברור מה בעצם בנינו פה.
def cnn_model(input_shape=(32, 32, 3)):
model = Sequential()
# ================================
# Convolutional Blocks
# ================================
# ----- Conv Block 1: 32 Filters, MaxPool. -----
model.add(Conv2D(filters=32, kernel_size=3, padding='same', activation='relu', input_shape=input_shape))
model.add(Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# ----- Conv Block 2: 64 Filters, MaxPool. -----
model.add(Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# ----- Conv Block 3: 64 Filters, MaxPool. -----
model.add(Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# ================================
# Classifier
# ================================
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(10, activation='softmax'))
return model
אחרי שיצרנו פונקציה שמגדירה מודל ומחזירה אותו, נוכל לקרוא לה ולהציג סיכום שלה. אני מציע לכם לנסות להבין כמה דקות מה אנחנו רואים פה. באופן אישי, מצאתי את הסיכום דרך מעניינת לראות את המודל שלנו ממומש, והדבר היותר מעניין זה כמות הפרמטרים אותם אנחנו נאמן; 670 אלף - הרבה, נכון?
model = cnn_model()
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
conv2d_1 (Conv2D) (None, 32, 32, 32) 9248
max_pooling2d (MaxPooling2 (None, 16, 16, 32) 0
D)
conv2d_2 (Conv2D) (None, 16, 16, 64) 18496
conv2d_3 (Conv2D) (None, 16, 16, 64) 36928
max_pooling2d_1 (MaxPoolin (None, 8, 8, 64) 0
g2D)
conv2d_4 (Conv2D) (None, 8, 8, 64) 36928
conv2d_5 (Conv2D) (None, 8, 8, 64) 36928
max_pooling2d_2 (MaxPoolin (None, 4, 4, 64) 0
g2D)
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 512) 524800
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 669354 (2.55 MB)
Trainable params: 669354 (2.55 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Compile המודל #
אחרי שהגדרנו את כל השכבות במודל וראינו איך הוא נראה, נצטרך לבצע Compile על המודל. ממה Compile מורכב?
Loss Function- אופן השוואת חיזוי המודל לבין התוצאה האמיתית. במקרה שלנו נשתמש ב-categorical_crossentropy, שמתאים לבעיות זיהוי תוויות one-hot encoded.Optimizer- אלגוריתם כיוונון המשקלים על בסיס ה-Loss. במקרה שלנו נשתמש ב-RMSProp.Metrics- מטריקות שיכולות לעזור למודל להבין את נכונותו (בדומה ל-Loss). נשתמש ב-accuracy.
model.compile(
optimizer=CompileConfig.OPTIMIZER,
loss=CompileConfig.LOSS,
metrics=CompileConfig.METRICS
)
אימון המודל #
הגיע הרגע לו חיכינו ונתחיל לאמן את המודל, בעזרת הפונקציה model.fit:
X_train- התמונות שלנו.y_train- ה-Labels של התמונות.batch_size- מגדיר את כמות הדוגמאות שנשתמש עבור כל עדכון של המשקלים במודל. לדוגמא,BATCH_SIZEבגודל 32 אומר שה-optimizer ישתמש ב-32 דוגמאות מתוךX_trainלחישוב ה-gradient ועדכון המשקלים בכל סבב.epochs- מגדיר את כמות הפעמים שהמודל יעבור על כל המודל. לדוגמא, אםEPOCHSבגודל 10, אז המודל יעבור על כל ה-Dataset 10 פעמים.verbose- ידלוק במידה ונרצה logging בזמן האימון.validation_split- חלוקת ה-Dataset ל-70% אימון ו-30% ולידציה. אחרי כל epoch ביצועי המודל יחושבו על בסיסו. הפרדת Training ו-Validation מאפשרת לנו למדוד את ביצועי המודל על בסיס תמונות שלא ראה לפני.
אחרי שנסיים לאמן את המודל, נקבל אובייקט history שמכיל רשומות שונות על ביצועי המודל בהם נשתמש על מנת להבין את ביצועי המודל.
history = model.fit(
X_train,
y_train,
batch_size=TrainingConfig.BATCH_SIZE,
epochs=TrainingConfig.EPOCHS,
verbose=1,
validation_split=TrainingConfig.SPLIT
)
Epoch 29/31
137/137 [==============================] - 46s 335ms/step - loss: 0.0595 - accuracy: 0.9807 - val_loss: 2.0921 - val_accuracy: 0.7112
Epoch 30/31
137/137 [==============================] - 44s 324ms/step - loss: 0.0595 - accuracy: 0.9813 - val_loss: 2.1037 - val_accuracy: 0.7174
Epoch 31/31
137/137 [==============================] - 45s 326ms/step - loss: 0.0495 - accuracy: 0.9831 - val_loss: 2.3880 - val_accuracy: 0.7089
בחינת ביצועי המודל #
בניתי פונקציה שמקבלת את המטריקות training and validation losses ו-training and validation accuracies, ופורסת אותם על גבי גרף שנוכל להשוות בינם ולהבין את ביצועי המודל בצורה ויזואלית ונוחה. ניגש לערכי המטריקות דרך אובייקט history אותו הגדרנו כחלק מאימון המודל.
def plot_training_history(history, metrics=("loss", "accuracy"), ylim_loss=(0, 5), ylim_acc=(0, 1)):
"""
Plots the training and validation loss and accuracy.
"""
for metric in metrics:
plt.figure(figsize=(12, 4))
train_metric = history.history[metric]
valid_metric = history.history[f"val_{metric}"]
plt.plot(train_metric, label=f'Training {metric.capitalize()}')
plt.plot(valid_metric, label=f'Validation {metric.capitalize()}')
plt.xlabel('Epoch')
plt.ylabel(metric.capitalize())
plt.title(f'{metric.capitalize()} Over Epochs')
ylim = ylim_loss if metric == "loss" else ylim_acc
plt.ylim(ylim)
plt.xlim(0, len(train_metric) - 1)
plt.legend()
plt.grid(True)
plt.show()
plot_training_history(history)
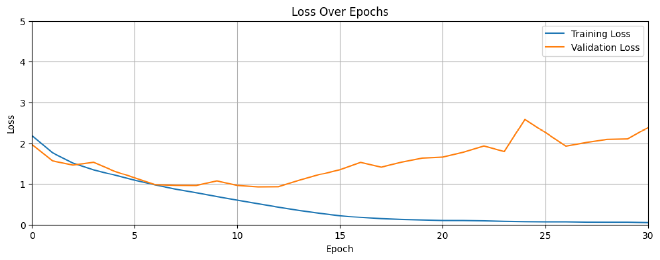
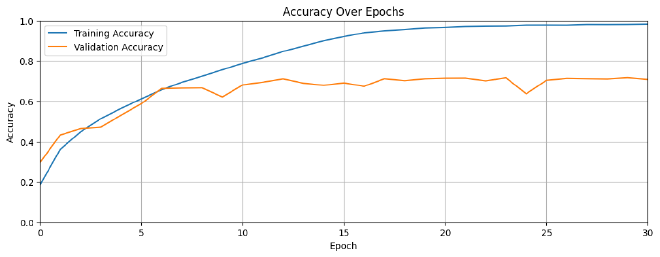
לפני שנבין מה בעצם קיבלנו בגרפים, נזכיר את ההבדל בין Loss לבין Accuracy:
- Loss - מספר סקלארי המודד את הפער בין חיזוי המודל לבין ה-Class האמיתי. זאת אומרת, ככול שה-Loss נמוך יותר, המודל מאומן טוב יותר.
- Accuracy - היחס בין סך החיזויים הנכונים למול מספר הרשומות ב-Dataset. לדוגמא, אם ערכו הוא 0.95, המודל זיהה נכון 95% מהפעמים.
בזמן שביצועי המודל על גבי ה-Training data מוצלח, הוא מתקשה לסווג תמונות חדשות שלא ראה לפני כן. איך הבנתי את זה? מצטבר פער אחרי בערך 10 epochs בין ה-Training ל-Validation. במילים אחרות, המודל שלנו סובל מ-Overfit ונצטרך לעשות התפשרות.
הוספת Dropout #
קיימים מספר טכניקות להימנעות מ-Overfit, אחת מהם היא הוספת שכבות Dropout. מה זה? שכבה שבצורה אקראית מכבה חלק מנוירונים בזמן האימון. כיבוי נוירונים מגביל את המודל מלשנן את ה-Training Data, ומאפשר לו לייצג קשרים כללים.
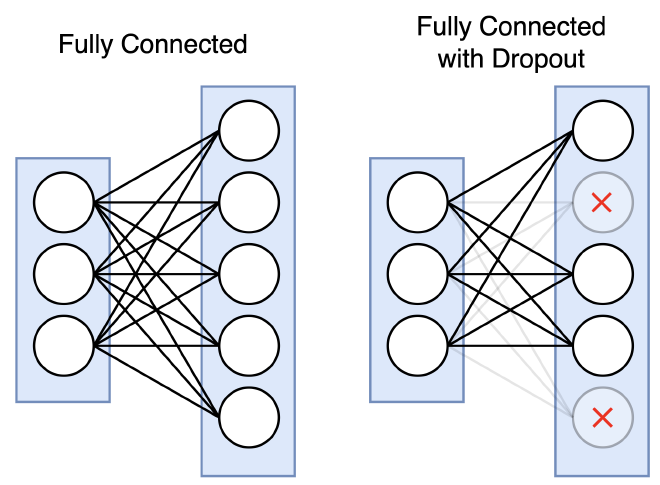
כמו שאפשר לראות, שכבת ה-Dropout תהיה אחרי שכבת Max Pooling ואחרי שכבת FC. עבור כל שכבת Dropout נגדיר את אחוז הנוירונים אותם נרצה לכבות אקראית בתהליך האימון.
מימוש המודל עם שכבת Dropout #
def cnn_model_dropout(input_shape=(32, 32, 3)):
model = Sequential()
# ================================
# Convolutional Blocks
# ================================
# ----- Conv Block 1: 32 Filters, MaxPool, Dropout -----
model.add(Conv2D(filters=32, kernel_size=3, padding='same', activation='relu', input_shape=input_shape))
model.add(Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# ----- Conv Block 2: 64 Filters, MaxPool, Dropout -----
model.add(Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# ----- Conv Block 3: 64 Filters, MaxPool, Dropout -----
model.add(Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# ================================
# Classifier
# ================================
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
return model
הגדרנו מודל חדש עם שכבות Dropout; בבלוקי Conv הגדרנו כיבוי אקראי של 25% מהנוירונים, וב-FC הגדרנו כיבוי אקראי של 50% נוירונים. עכשיו השלב הבא הוא ליצור אותו, לעשות compile ולאמן אותו, בדיוק באותה הדרך בה אימנו את המודל ללא שכבות Dropout. לאחר מכן נציג את התוצאה בגרפים דומים למה שהיה קודם.
model_dropout = cnn_model_dropout()
model_dropout.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
conv2d_1 (Conv2D) (None, 32, 32, 32) 9248
max_pooling2d (MaxPooling2 (None, 16, 16, 32) 0
D)
dropout (Dropout) (None, 16, 16, 32) 0
conv2d_2 (Conv2D) (None, 16, 16, 64) 18496
conv2d_3 (Conv2D) (None, 16, 16, 64) 36928
max_pooling2d_1 (MaxPoolin (None, 8, 8, 64) 0
g2D)
dropout_1 (Dropout) (None, 8, 8, 64) 0
conv2d_4 (Conv2D) (None, 8, 8, 64) 36928
conv2d_5 (Conv2D) (None, 8, 8, 64) 36928
max_pooling2d_2 (MaxPoolin (None, 4, 4, 64) 0
g2D)
dropout_2 (Dropout) (None, 4, 4, 64) 0
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 512) 524800
dropout_3 (Dropout) (None, 512) 0
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 669354 (2.55 MB)
Trainable params: 669354 (2.55 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
model_dropout.compile(
optimizer=CompileConfig.OPTIMIZER,
loss=CompileConfig.LOSS,
metrics=CompileConfig.METRICS
)
# Train the Model (with Dropout)
history = model_dropout.fit(
X_train,
y_train,
batch_size=TrainingConfig.BATCH_SIZE,
epochs=TrainingConfig.EPOCHS,
verbose=1,
validation_split=TrainingConfig.SPLIT
)
Epoch 29/31
137/137 [==============================] - 45s 329ms/step - loss: 0.5194 - accuracy: 0.8156 - val_loss: 0.6442 - val_accuracy: 0.7786
Epoch 30/31
137/137 [==============================] - 45s 325ms/step - loss: 0.5028 - accuracy: 0.8214 - val_loss: 0.6675 - val_accuracy: 0.7780
Epoch 31/31
137/137 [==============================] - 45s 329ms/step - loss: 0.5005 - accuracy: 0.8235 - val_loss: 0.6622 - val_accuracy: 0.7771
plot_training_history(history)
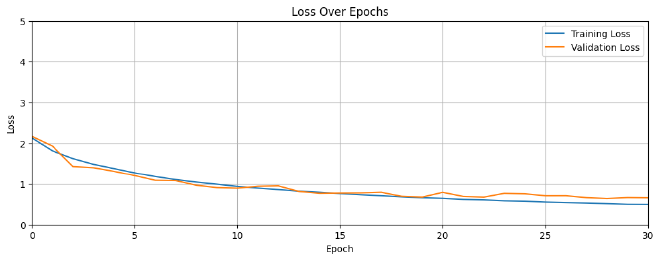
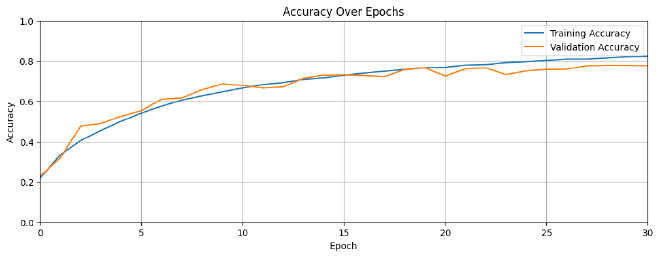
אפשר לראות עכשיו שהצלחנו להגיע לצמצום ההפרש בין ה-Training ל-Validation, ובכך תוספת שכבות Dropout עזרה לנו למנוע Overfit.
שמירה וטעינת המודל #
תהליך אימון זה משהו שלוקח כמה עשרות דקות ואנחנו לא רוצים לאמן אותו בכל פעם שנרצה להשתמש בו. לכן חשוב לדעת איך לשמור אותו אחרי האימון, ואיך לטעון אותו לשימושים בעתיד.
בעזרת פונקציית ()save נוכל לשמור את המודל בפורמט SavedModel. אחראי שנקרא לפונקציה זו, תיווצר תיקייה חדשה בה יהיה: הגדרות המודל, משקלי המודל ותוצאות סטטיסטיות על המודל.
model_dropout.save('model_dropout')
INFO:tensorflow:Assets written to: model_dropout/assets
INFO:tensorflow:Assets written to: model_dropout/assets
לאחר מכן, נוכל לטעון אותו מתי שנרצה באמצעות פונקציית ()load_model
reloaded_model_dropout = models.load_model('model_dropout')
ביצועי המודל #
ישנם מספר דרכים שנוכל למדוד את ביצועי המודל (Model Evaluation). נוכל לחשב את ה-accuracy על גבי ה-test dataset, נוכל להסתכל בצורה גרפית על החיזוי של המודל, ונוכל לעשות confusion matrix.
Test Dataset #
נטען את התמונות שהמודל לא ראה שנמצאים ב-X_test y_test, ובעזרת פונקציית evaluate נחזה את תחזית המודל למול הערך בפועל.
test_loss, test_acc = reloaded_model_dropout.evaluate(X_test, y_test)
print(f"Test accuracy: {test_acc*100:.3f}")
313/313 [==============================] - 4s 12ms/step - loss: 0.6817 - accuracy: 0.7705
Test accuracy: 77.050
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
דגימת תמונות #
נבחר בצורה רנדומלית תמונות מתוך ה-Test, ונראה מה החיזוי של המודל למול מה שבפועל יש בתמונה.
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
def evaluate_model(dataset, model, y_test, class_names):
# Number of rows and columns for the plot grid
num_rows, num_cols = 3, 6
# Retrieve a batch of images from the dataset
data_batch = dataset[0:num_rows*num_cols]
# Get model predictions
predictions = model.predict(data_batch)
# Initialize variables
num_matches = 0
# Create plot
plt.figure(figsize=(20, 8))
for idx in range(num_rows * num_cols):
ax = plt.subplot(num_rows, num_cols, idx + 1)
plt.axis("off")
plt.imshow(data_batch[idx])
pred_idx = tf.argmax(predictions[idx]).numpy()
truth_idx = np.argmax(y_test[idx])
title = f"{class_names[truth_idx]} : {class_names[pred_idx]}"
title_color = 'g' if pred_idx == truth_idx else 'r'
plt.title(title, fontsize=13, color=title_color)
num_matches += (pred_idx == truth_idx)
acc = num_matches / (num_rows * num_cols)
print(f"Prediction accuracy: {acc:.2f}")
plt.show()
evaluate_model(X_test, reloaded_model_dropout, y_test, class_names)
1/1 [==============================] - 0s 24ms/step
Prediction accuracy: 0.89

Confusion Matrix #
נשתמש ב-confusion matrix כאשר נרצה להשוות בין הערך האמיתי לבין הערך החזוי של Labels. מטריצה זו מאפשרת לנו לאמוד את נכונות המודל לרמת Class. השוואה לרמת Class תוכל להראות לנו האם המודל מתבלבל בין Classes, ונוכל לפי זה לדייק אותו.
# Generate predictions for the test dataset.
predictions = reloaded_model_dropout.predict(X_test)
# For each sample image in the test dataset, select the class label with the highest probability.
predicted_labels = [np.argmax(i) for i in predictions]
313/313 [==============================] - 4s 12ms/step
# Convert one-hot encoded labels to integers.
y_test_integer_labels = tf.argmax(y_test, axis=1)
# Generate a confusion matrix for the test dataset.
cm = tf.math.confusion_matrix(labels=y_test_integer_labels, predictions=predicted_labels)
# Plot the confusion matrix as a heatmap.
plt.figure(figsize=[14, 7])
sns.heatmap(cm, annot=True, fmt='d', annot_kws={"size": 12})
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Truth')
plt.show()
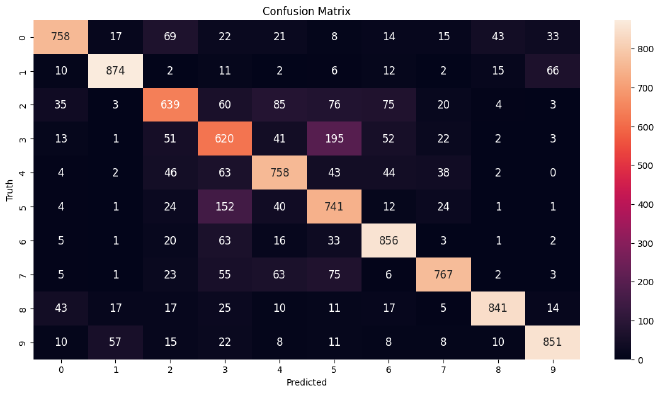
נוכל לראות שהמודל מתבלבל בין כלבים וחתולים, ובין משאיות ומכוניות. הבלבול הזה הגיוני, למול רזולוציית התמונות שהיא מאוד נמוכה.
Explainable AI #
לדעתי, חשוב לדעת להסביר את תוצאות המודל לא פחות מנכונותו. לכן, החלטתי להקדיש חלק נוסף למאמר, שהוא Explainable AI. יש תפיסה שאומרת שמודלי בינה מלאכותית הם קופסאות שחורות שלא ניתן להסביר אותם, ולקחתי על עצמי את האתגר להסביר מודל CNN.
שכבות המודל #
כמו שלמדנו, למודל CNN ישנם שכבות Conv עם גדלים שונים, עומק ו-Filters. חשבתי שיהיה מעניין לראות איך התמונה משתנה לאורך התמונה.
- נשמור במערך
conv_layer_indicesמייצג את שכבות ה-Conv שיש לנו במודל (לפי index). - נבחר 5 תמונות בצורה אקראית מ-
X_test. - נציג את התמונות.
- עבור כל תמונה:
- ניקח את ה-filter האחרון בשכבה האחרונה בכל בלוק Conv.
- נבצע פעולת Conv לתמונה כך שהבלוק השני מקבל את התוצאה של השני וכך הלאה.
- נציג את ה-filter ואת תוצאת ההכפלה.
conv_layer_indices = [0, 1, 4, 5, 8, 9]
# Randomly select 5 images from X_test
random_indices = np.random.choice(X_test.shape[0], size=5, replace=False)
selected_images = X_test[random_indices]
# Create a figure to display the original images once
plt.figure(figsize=(20, 4))
# Add an empty subplot for alignment
plt.subplot(1, 6, 1)
plt.axis('off')
# Display original images
for j in range(5):
plt.subplot(1, 6, j + 2)
plt.imshow(selected_images[j].astype('uint8')) # Assuming the images are normalized
plt.axis('off')
plt.show()
# Loop through the convolutional layer indices
for idx in conv_layer_indices:
filters, _ = model.layers[idx].get_weights()
# Get the last kernel from the layer
last_kernel = filters[:, :, :, -1]
# Create a truncated model that ends at this layer
truncated_model = Model(inputs=model.inputs, outputs=model.layers[idx].output)
# Generate feature maps for the selected images
feature_maps = truncated_model.predict(selected_images, verbose=0) # Setting verbose to 0
# Create a figure to hold the last kernel and the affected images
plt.figure(figsize=(20, 4))
# First subplot: Last kernel
plt.subplot(1, 6, 1)
plt.imshow(last_kernel[:, :, 0], cmap='gray') # Assuming single channel (grayscale)
plt.axis('off')
# Next subplots: Affected images
for j in range(5):
affected_image = feature_maps[j, :, :, -1]
plt.subplot(1, 6, j + 2)
plt.imshow(affected_image, cmap='gray')
plt.axis('off')
plt.show()



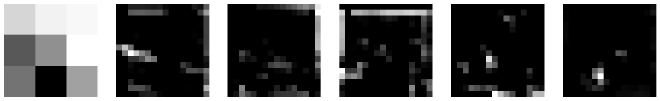
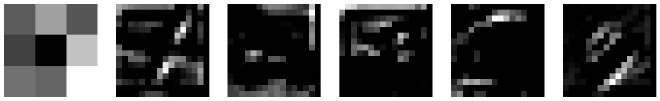
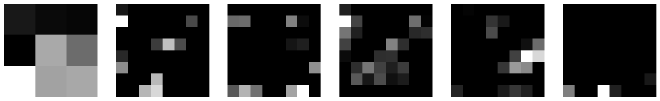

עכשיו אתם יכולים לשער באילו אזורים בתמונה המודל מסתכל, מה הדפוסים שהמודל זיקק ואיך התמונה מעובדת לאורך המודל.
עייני המודל #
אחרי שראינו איך המודל מעבד את התמונה, הדבר המתבקש הוא לראות את האזורים בתמונה בהם הוא מתמקד, מה הוא חוזה שיש בתמונה ומה יש בפועל בתמונה.
- בחירת תמונות
- נבחר 50 תמונות בצורה אקראית מ-
X_test. - נוציא את שם האובייקט הנמצא בתמונה.
- נבחר 50 תמונות בצורה אקראית מ-
- תחזית - עבור כל תמונה, נבחן את התחזית המודל בעזרת פונקציית
()predict. - תתי-מודל - נפרק את המודל CNN לחלקים על פי
conv_layer_indices(המיקומים של בלוקי Conv במודל). - המחשה - נגדיר את
figו-axesשישמשו אותנו להצגת התמונות. - חישוב מפת חום - עבור כל תמונה:
- נציג את גרסת המקור שלה.
- נחשב את תוצאת ההכפלה של התמונה בשכבות המפורקות של המודל.
- הצגת את תוצאת ההכפלה ואת החיזוי של המודל.
- נבצע התאמות לתצוגה.
# Randomly select 50 images from X_test
num_images = 50
random_indices = np.random.choice(X_test.shape[0], num_images, replace=False)
selected_images = X_test[random_indices]
selected_labels = [class_names[label[0]] for label in y_test[random_indices]]
# Get the model's predictions for the selected images
predictions = model.predict(selected_images)
selected_labels = [class_names[label[0]] for label in y_test[random_indices]]
# Create sub-models to get the output of each selected conv layer
layer_outputs = [model.layers[i].output for i in conv_layer_indices]
sub_models = [Model(inputs=model.inputs, outputs=output) for output in layer_outputs]
# Initialize a figure for plotting
fig, axes = plt.subplots(num_images // 2, 4, figsize=(20, (num_images // 2) * 4))
for i in range(num_images // 2):
for j in range(2):
idx = i * 2 + j
img = selected_images[idx]
label = selected_labels[idx]
pred_label = predicted_labels[idx]
# Display original image
axes[i, j * 2].imshow(img)
axes[i, j * 2].set_title(label)
axes[i, j * 2].axis('off')
# Compute and plot heatmaps
heatmaps = []
for sub_model in sub_models:
conv_output = sub_model.predict(img[np.newaxis, ...], verbose=0)
resized_heatmap = resize(conv_output[0, :, :, -1], (img.shape[0], img.shape[1]))
heatmaps.append(resized_heatmap)
# Sum the resized heatmaps
summed_heatmap = np.sum(heatmaps, axis=0)
# Normalize the summed heatmap
summed_heatmap = (summed_heatmap - np.min(summed_heatmap)) / (np.max(summed_heatmap) - np.min(summed_heatmap))
# Display the overlay
axes[i, j * 2 + 1].imshow(img, alpha=1.0)
axes[i, j * 2 + 1].imshow(summed_heatmap, cmap='jet', alpha=0.6)
axes[i, j * 2 + 1].set_title(pred_label) # Set the title to the model's prediction
axes[i, j * 2 + 1].axis('off')
plt.tight_layout()
plt.show()
לא סתם בחרתי להראות 50 תמונות. אפשר להבין הרבה מאוד מהמודל מהתצוגה הזו. לדוגמא; שהוא מזהה חתול לפי קווי המתער שלו, שהוא מזהה סוס על פי הרגליים, שהוא מזהה מכונית לפי קווי המתער שלה ועוד מאפיינים מעניינים. בנוסף, נוכל לראות למה המודל מתבלבל בין תוויות, ולבצע עדכונים בהתאמה למודל או ל-Dataset. למרות שמדובר על גודל מאוד קטן של תמונות, אפשר לזקק תובנות מעניינות מהמודל שבנינו.

מילות סיכום #
במאמר הזה למדנו איך להשתמש ב-Tensorflow על מנת לבנות ולאמן מודל CNN בסיסי. למדנו על Overfit, למדנו על הוספת שכבות Dropout על מנת להפחית את ה-Overfit. למדנו על טכניקות לבדיקת תוצאות המודל, ולבסוף המחשנו את ראיית המודל.